We often get asked if Kerika has an integration with Git. The short answer is “No”, but the longer answer is more nuanced…
We use Git ourselves for managing our own source code and other software assets.
Git was designed from the git go (ha!) to be used by distributed teams, having originated with the Linux kernel team, perhaps the most important distributed team in the whole world, so it made perfect sense for us to use it: it works across operating systems, and a number of simple GUIs are now available for managing your various source-code branches.
We simply embed the git references within cards on our project boards: sometimes in the chat conversation attached to a card, but more often within the card’s details.
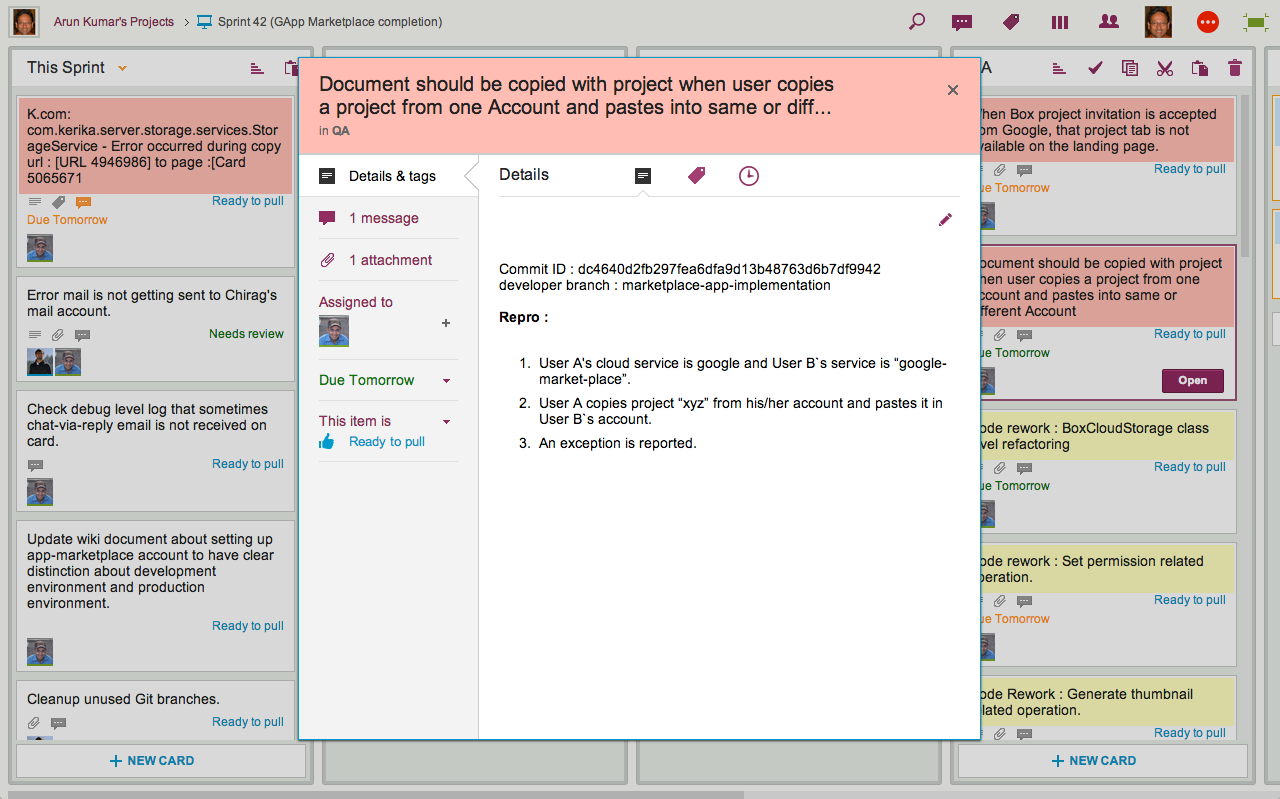
Here’s an actual example of a bug that we fixed recently:
Example of Git integration
We use multiple Git branches at the same time, because we put every individual feature into a separate branch.
That’s not a fixed rule within Git itself; it’s just our own team’s practice, since it makes it easier for us to stick with a 2-week Sprint cycle: at the end of every 2 weeks we can see which features are complete, and pull these git branches together to build a new release.
So while Kerika doesn’t have a direct integration with Git, it’s pretty easy to use Kerika alongside Git, or other source management systems.
One of our users wrote in last night with this great story, which we wanted to share with you…
I did a one hour webinar for the software company (Software AG) that we develop all of our software with as they were impressed with the way we were using their software development environment (NaturalOne).
I threw a little Kerika spice into my presentation as it has become such an important part of our development environment and I actually used it to prepare my presentation.
Instead of preparing the presentation by myself I used a Kerika project and had my software developers contribute cards and instructions in the areas that they specialized.
While I was doing a live presentation I was referring to the cards on my other monitor and swiping them to the ‘Done’ column as I completed them.
I know you like to hear stories about how people use your software and this worked very well for this presentation. It was recorded and I will send you a link to it once it is published. It might put you to sleep at night, except for the Kerika part.
Here at Kerika, we often get asked how we do Scrum as a distributed team.
Here’s the model we have evolved, which works for us mainly because we are the very essence of a distributed Agile team: we have people working together on the same product from locations that are 10,000 miles apart!
And this means that we are the most enthusiastic consumers of our products: we use Kerika to manage every part of our business and we only build what we would ourselves love to use.
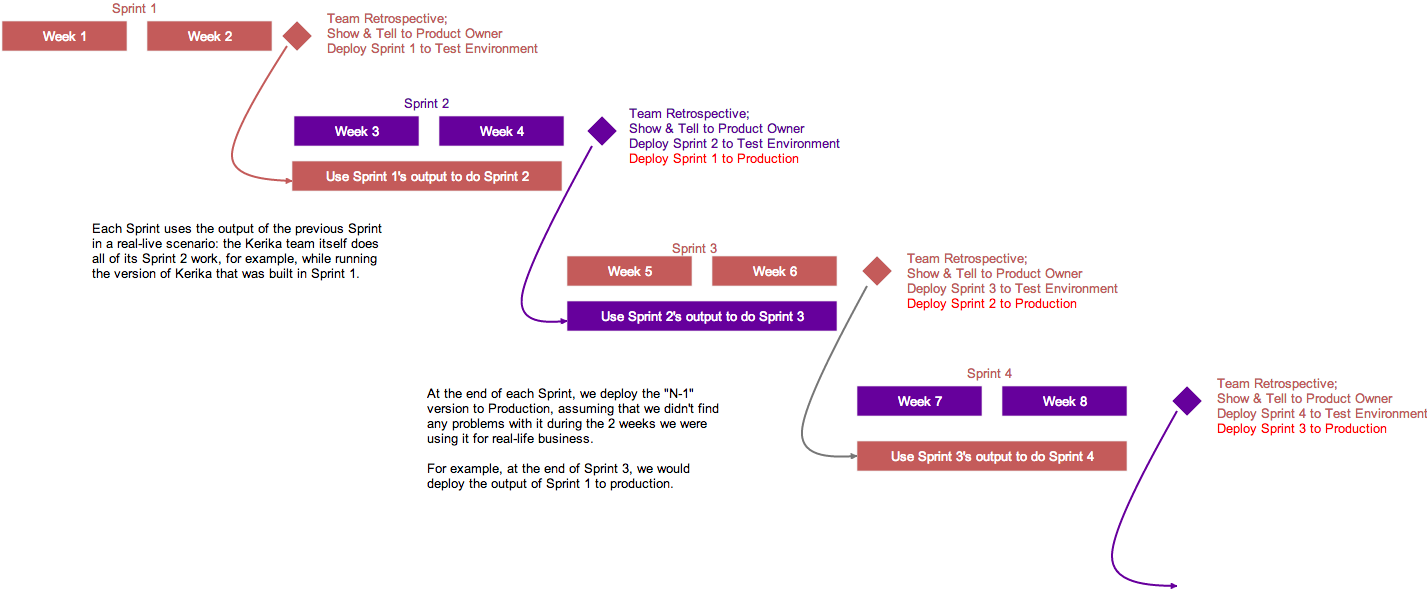
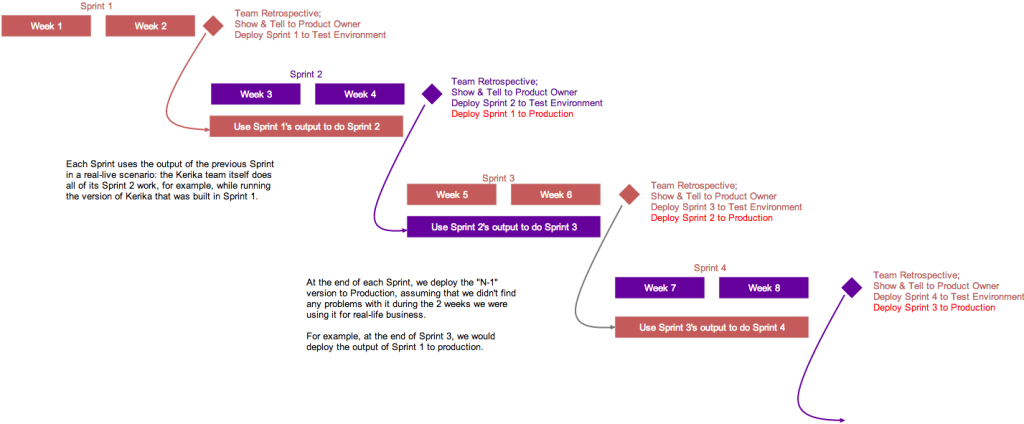
Here’s the basic outline of our Scrum model:
Kerika’s model for 2-week Sprints
Each Sprint is 2 weeks long: that that works well for us; other folks might find that 3 weeks or 4 weeks i better. Pick what works for you.
Each Sprint begins with Sprint Planning, where the Scrum Team gets together with the Product Owner to decide which cards will be pull from our main Product Backlog into the Sprint Backlog.
Each Sprint is organized as a separate Scrum Board: this makes it really easy for us to concentrate upon needs to get delivered in that particular Sprint, without getting distracted by what was done in the past or what remains to be done.
And Kerika makes it really easy to pull cards (literally!) from the Backlog onto a Scrum Board, and then hide the Backlog from view so it doesn’t distract the Team while the Sprint is underway.
Half-way the Sprint, at the end of the first week, we do a gut-check: does the Sprint look like it is going reasonably well? We don’t ask if it is going perfectly: almost no Sprint does; what we are looking for is any indication that the Sprint is going to severely under-deliver in terms of the Team’s commitments to the Product Owner.
We could do these gut-checks every day during our Daily Standups, but in the first part of a Sprint cycle these can often give us false positives: it’s easy to tell early on if a Sprint is going to be disastrous, but it’s hard to tell for sure that it is actually going to end well. But about midway through the Sprint we start to have a more reliable sense for how things may turn out.
In keeping with the Scrum model, our goal is to complete a potentially shippable set of features and bug fixes with each Sprint, although this doesn’t necessarily mean that we will always ship what gets built after each Sprint. (More on that later.)
For each feature or bug, however large or small, we make sure that we have design and testing baked into the process:
An analysis document is prepared and attached to the card, either as a Google Doc or as Box document. (We had been using Kerika+Google exclusively for years, but have recently switched to Kerika+Box since we completed our Box integration.)
The document is often just a few paragraphs long, because we always take cards representing large features (or other big work items) and break them up into smaller cards, so that no card is likely to take more than a day’s work. Kerika makes it really easy to link cards together, so it’s easy to trace work across multiple cards.
For bugs, the attached document describes the expected behavior, the actual behavior, and the root cause analysis. Very frequently, screenshots showing the bugs are attached to the cards.
For new features, several documents may be attached, all quite small: there may be a high-level analysis document and a separate low-level design document.
For all features and bugs, we do test planning at the time we take on the work: for back-end (server) work we rely primarily on JUnit for writing automated tests; for front-end (UI) work we have found that automated testing is not very cost-effective, and instead rely more on manual testing. The key is to be as “test-driven” in our development as possible.
There are several benefits from doing formal planning, which some folks seem to view as being antithetical to an Agile model:
It helps find holes in the original requirements or UI design: good technical analysis finds all the edge cases that are overlooked when a new feature is being conceptualized.
It helps ensure that requirements are properly interpreted by the Team: the back-and-forth of analysis and reviewing the requirement helps ensure that the Product Owner and the Team are in synch on what needs to get done, which is especially important for new features, of course, but can also be important to understand the severity and priority of bugs.
It deliberately slows down the development pace to the “true” pace, by ensuring that time and effort for testing, especially the development of automated tests, is properly accounted for. Without this, it’s easy for a team to quickly hack new features, which is great at first but leads to unmaintainable and unstable code very soon.
At the end of the 2-week cycle, the Team prepares to end the Sprint…
We like to talk about Sprints as “buses”: a bus comes by on a regular schedule, and if you are ready and waiting at the bus stop, you can get on the bus.
But if you are not ready when the bus comes along, you are going to have to wait for the next bus, which thankfully does come by on a regular 2-week schedule.
This metaphor helps the Team understand that Sprints are time-boxed, not feature-boxed: in other words, at the end of every 2 weeks a Sprint will end, regardless of whether a feature is complete or not. If the feature is complete, it catches the bus; otherwise it will have to wait for the next bus.
And here’s where the Kerika team differs from many other Scrum teams, particularly those that don’t consume their own products:
At the end of each Sprint, we do the normal Sprint Retrospective and Show & Tell for the Product Owner.
But, we also then take the output of the Sprint and deploy it to our test environment.
Our test environment is the one we actually use on a daily basis: we don’t use the production environment as often, preferring to risk all of our work by taking the latest/greatest version of the software on the test environment.
This forces us to use our newest software for real: for actual business use, which is a much higher bar to pass than any ordinary testing or QA, because actual business use places a higher premium on usability than regular QA can achieve.
(And, in fact, there have been instances where we have built features that passed testing, but were rejected by the team as unusable and never released.)
This is illustrated above: the version of Kerika that’s built in Sprint 1 is used by the team to work on Sprint 2.
This is where the rubber meets the road: the Kerika Team has to build Sprint 2, while using what was built in the previous Sprint. If it isn’t good enough, it gets rejected.
At the end of Sprint 2, we will release the output of Sprint 1 to production. By this time it will have been used in a real sense by the Kerika Team for at least 2 weeks, post regular QA, and we will have a high confidence that the new features and bug fixes are solid and truly usable.
We could summarize our model by saying that our production releases effectively lag our Sprint output by one Sprint, which gives us the change to “eat our own dogfood” before we offer it to anyone else.
We are now dealing with two different user communities!
People are signing up for our new Kerika+Box product, and we are continuing to grow our Kerika+Google user base.
Next up: we are upgrading our Google Apps Marketplace integration to also use OAuth 2.0, so that all logins to Kerika will be with OAuth 2.0, across all platforms.
The background to this work is slightly wonky, and reflects the way Google Apps Marketplace has evolved within the Google ecosystem.
If you sign up for Kerika+Google today, you actually go through a OAuth 2.0 authentication and authorization process with Google, which gives us your basic profile information (name, email, photo) that we use to set up your Kerika+Google account, as well as access to your Google Docs.
Google has deprecated OAuth 1.0, so we are updating our Google Apps Markeplace to also work with OAuth 2.0, just like a regular sign-up through Kerika.com.
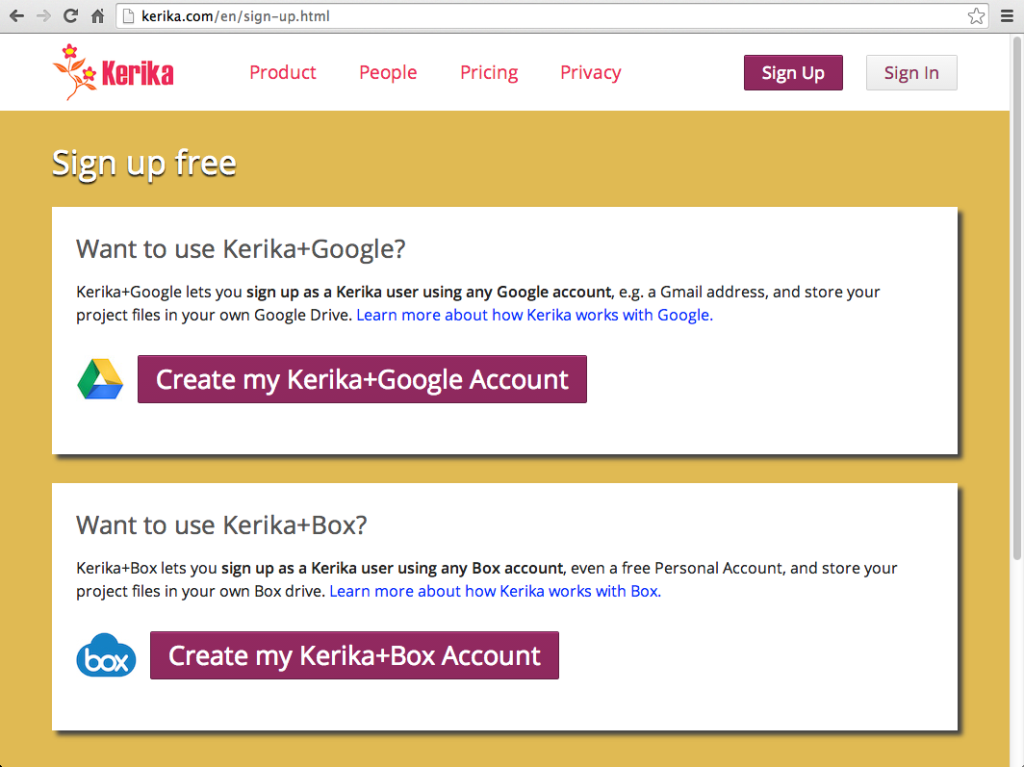
This change will not affect any existing users: the most visible effect will be on our Sign Up page, which will start to show three options for new users:
Sign up for a Kerika+Box account: this will work as it does today – it will use OAuth 2.0 to set up a Kerika account using your Box credentials (name, email address, and access to your Box account to store your Kerika-related files).
Sign up for a Kerika+Google account: this will also work as it does today – it will use OAuth 2.0 to set up a Kerika account using your regular Google credentials (e.g. Gmail ID, YouTube ID) and store your Kerika-related files in your Google Drive.
On LinkedIn’s Scrum Alliance group someone recently posed this question:
Which is more effective agile software project management tool MS Project or a agile software project management tool for implementing scrum?
Here’s my response:
I started using MS Project around 1989 — must have been close to v1.0, I imagine — and even back then, when it was a relatively simple tool, it never delivered enough utility to warrant the immense hassle of trying to keep it updated so that it actually reflected the reality of a fast-moving project.
The phrase that came to mind often was “I have to feed the beast again“, i.e. I have to spend hours each day trying to map all the real-time changes that were happening in the real-world to the fake world modeled in MS Project.
The MS Project world wasn’t fake because I was incompetent: it was fake because it was always instantly out-of-date.
And as MS Project has gotten larded with more bells and whistles, it has never been able to address its fundamental shortcoming: it is a theoretical model of what you would like your project to be, rather than a practical/actual reflection of what your project is.
So, even back in the 1980s, before people were talking about Agile and Scrum, we were all actually living in an Agile/Scrum world; we just didn’t have that realization, and we didn’t have the appropriate tools to deal with a fast-changing project environment.
At Kerika, we live and breathe in a distributed Agile world: our team is spread out between Seattle and India, which means we never have any overlapping time, but by using Kerika scrum boards we are in perfect synch with each other.
We know exactly what everyone else is up to, and we are able to process, on average, 10-12 cards per week, per person, on a sustained basis.
Kerika also has a whiteboard capability so we are able to do brainstorming and design work.
Is MS Project useful for anything at all? Yes, if your project…
a) Is considered immutable from the very start.
An example would be a government contract which is negotiated up-front in painful detail, and your success is defined only in terms of whether you delivered exactly what was specified, not whether the final product was useful. (Business-as-usual for most Federal contracts.)
b) Every aspect of the technology has been prototyped, tested, and proven already, so uncertainties are minimized.
This is an interesting use-case of mixing Scrum and Waterfall that’s not explored very often, where you use Agile to do your R&D and figure out workable solutions to your biggest uncertainties, and then use Waterfall to build the final version.
At long last, and with considerable effort, we finished and released Kerika+Box: a seamless integration of Kerika with the Box cloud storage platform.
Kerika+Box works just like Kerika+Google, the old integration of Kerika with Google Drive: both offer a complete work management system that works seamlessly with your cloud storage platform of choice.
We are really excited about this new release; we have found that there are a ton of advantages to using Box as a cloud storage platform:
It’s free for personal use, which means it’s easy to get started.
You can sign up with an existing email address: you don’t need to get a new ID.
It’s got the best security and enterprise management features of any cloud storage platform out there.
The company is very accessible and offers great support.
We have also updated our website, to make it more responsive (i.e. display better on mobile devices), and we have included a number of customer profiles to give you an idea of the very broad range of people who are using Kerika.
We have a growing community of users in various agencies within Washington State government, and we are happy to provide the essential project management and team collaboration tool needed to achieve the Governor’s mandate for “Lean Government”.
Among other agencies, we are proud to serve people in:
To help folks within Washington State agencies understand how (and when and why…) they should Kerika, we have partnered with the state’s Office of the CIO to produce a quick guide to Using Kerika for State Government Work:
(The ninth in a series of blog posts on why we are adding integration with Box, as an alternative to our old integration with Google Drive.)
We have been doing internal testing (“eating our own dogfood”) of Kerika+Box for the past three weeks, and the results have been much better than we expected!
We have found very few bugs so far, which is great — it’s feels like a huge vindication of our decision to invest several Sprints in improving our internal QA processes, clearing the backlog of old bugs, and generally improving our software development processes with code reviews across the board, for even the smallest changes.
In other words, we didn’t move fast and break things: we moved slowly and broke nothing. Which makes sense when you have paying customers who rely upon your product to run their businesses…
Since Kerika makes it really easy to have multiple backlogs in a single account, we put all the OAuth and infrastructure work in a separate backlog, allowing a part of the team to concentrate on that work somewhat independently of other, more routine work like bug fixes and minor usability updates.
And, as before, put every feature in a separate git branch, making it easy to merge code as individual features get done.
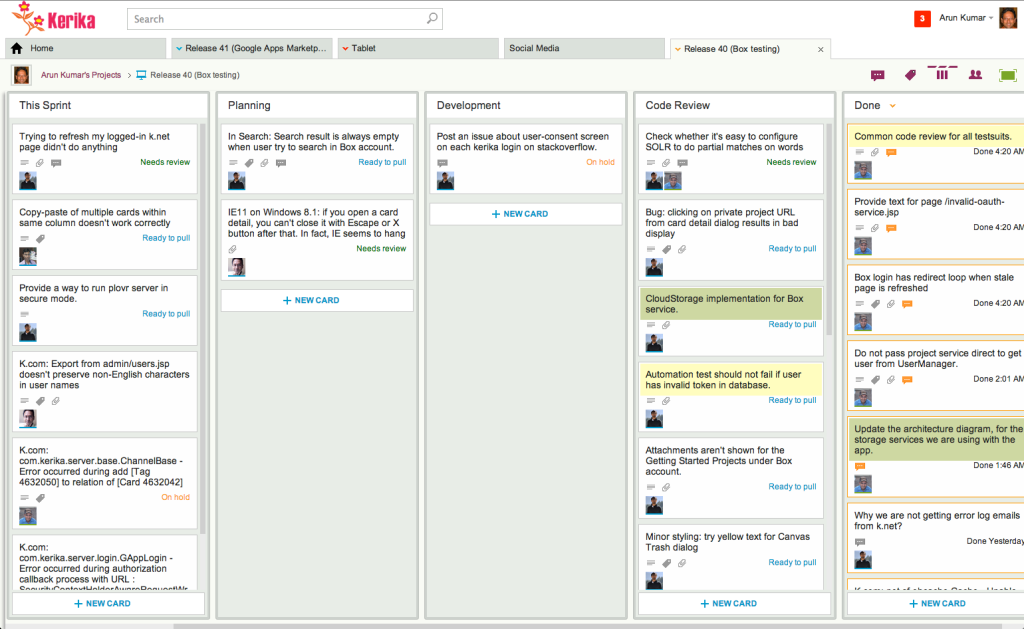
Here’s what our Box QA board looks like, right now:
Box QA board
The user interface for Kerika+Box is essentially the same as for Kerika+Google, with a few quirks:
Box requires more frequent logins: Google provided us with relatively long-lived refresh tokens, so a user could close a Kerika browser tab and reopen it a day later and log right back in.
With Box, you are going to see a login screen much more often, along with a screen asking you to re-authorize Kerika as a third-party app that can access your Box account.
This is kind of irritating, but apparently unavoidable: from what we have found on Stack Overflow, Bug views this as a feature rather than a bug.
The other, really big difference is that files are edited offline rather than in the browser itself: when you click on the Edit button, you will end up downloading a local copy of the file, using Microsoft Office for example, and then when you do a Save of that file, your latest changes are uploaded automatically to the cloud.
Here’s what you see when you open a file attached to a card on a Kerika board, when you use Kerika+Box:
Example of opening a file within Box
This works great most of the time, except when two people are making changes simultaneously: in that situation, Google’s in-browser editing seems a lot more convenient.
On the other hand, downloading local copies of files means that you get the full power of Microsoft Office, and we know that’s very important for some of our users, e.g. consultants dealing with complicated RFPs or government users dealing with official documents.
Performance also seems a little less than Google Drive, although we would stress that this is highly variable: while Google Drive files generally open within 1-3 seconds in a new browser tab, they can take much longer if Google’s servers are slow.
Overall, we are very pleased with Kerika+Box: we are planning to do all of our new development with this new platform, to continue eating our delicious dogfood ;-)
Another question answered on LinkedIn’s Scale Agile group: The team is facing a high Technical debt before adopting Scrum. Now, they want to fix this. How could they include this in the Sprint?
If you already have a lot of technical debt, I would recommend that the first few Sprints do nothing but clear the most expensive debt.
The trick is to persuade the Product Owner that this is necessary, because it means deferring any delivery of “real features” while the debt is paid down.
Note that I say “paid down” rather than “paid off”: in my experience, there is rarely an opportunity to completely pay off technical debt and have a clean Product Backlog with nothing in it but nice user stories that deliver tons of end-user functionality.
At Kerika, we have found that we accumulate some debt almost continuously, and that this is unavoidable even though we are using Scrum.
Purists might argue that a true Scrum model eliminates technical debt, but this is unrealistic when you are dealing with a fast moving market and are focused on rapidly improving your product.
Periodically, we devote an entire Sprint to paying down technical debt. We did one fairly recently because we are in the process of adding some substantial new functionality: Kerika will now become the first Scrum/Kanban/Scrumban tool that has full integration with both Google Drive and Box for sharing project files within distributed team ;-)
Because this was a major platform enhancement, we took a 3-week Sprint to pay down our technical debt by clearing a bunch of bugs and server exceptions that individually were never going to make it to the top of the Product Backlog.
The Kerika tool makes it really easy to tag items, so it was easy for us to find all the bugs that were in our (rather large) Product Backlog and we cleared nearly 50 items.
Actually, this was our second debt payoff Sprint this year: in April, the Heartbleed scare prompted us to do a full internal review of our security processes, which morphed into a full review/overhaul of our QA and other software development infrastructure/process stuff, and we spent an entire Sprint to significantly clean up a bunch of stuff that had been moldering a while.
For what it’s worth, we generally do an all-hands-on-deck Sprint to pay down debt: we don’t try to sneak in any new product features because I find that it sends a confusing message to the team about the importance of paying down the debt.
I said earlier that often the big challenge is convincing the Product Owner of the need to devote a Sprint or two to pay down debt; in our case that’s relatively easy because I am the founder/CEO and buy into the idea ;-) but I do believe that if you are going to pay down debt, you need to do it with serious intent and get everyone focused on that, which means the Sprint is all about debt, not new goodies.
I recently offered my thoughts to the Scrum Alliance group on LinkedIn, on the discussion thread on whether
Kanban is a better way to manage support/maintenance work than scrum. I thought you might find it interesting:
Kanban is generally a better model for support/maintenance: these tasks tend to trickle in, so trying to handle them with a conventional Product Backlog is often awkward.
Support/maintenance tasks are also usually unrelated to each other: one bug fix may have nothing to do with another.
This makes for a different metaphor than Scrum/Product Backlog where there is some presumption that user stories and tasks, while perhaps independent, are at least part of a larger product or release theme.
If you did support/maintenance tasks in a Sprint, that Sprint would have no overarching theme which I strongly believe is essential for success with Scrum teams.
And if any team doing support/maintenance with Scrum will quickly realize their Sprints are unlike those of other teams that are doing product development with Scrum.
I would view your questions about swimlanes as arising from a misfitting metaphor: instead of using swimlanes, you would be better off using tags, and then filtering your board as needed to see all support/maintenance tasks related to a particular subsystem or process or person. E.g. “show me all the tasks related to the database schema”.
We use our own product (Kerika) of course, and we do all of our new product development with Scrum Board, and support/maintenance with Kanban boards since Kerika lets you easily have both kinds of boards.
We use multiple tags on each card on both the Kanban and Scrum Boards, so we can filter and search, e.g. “show everything related to our Google Drive integration”.
These filtered views are much more effective and flexible than trying to organize your board with swimlanes, because each card can have multiple tags, whereas with swimlanes a card would be in only one swimlane at any time.
Also, this arrangement gives us flexibility to move from Kanban to Scrum and back: for example, if a support/maintenance card that originally landed on a Kanban board is later deemed to be significant enough to handle as part of product development, we can just cut-and-paste that card from the Kanban board to the Scum Board, and Kerika brings along all the content, history, attachments, chat, etc.