We just spent an hour trying, fruitlessly, to set up a “Google Hangout on Air”, and about the only thing we can conclude is that all those folks who are worried about Google’s plan for world domination can relax: Google isn’t close to having a single ID to track everyone.
In order to do a Hangout on Air (a public Hangout, that up to 10 people? can view), you need to have a YouTube channel connected to your Google+ account.
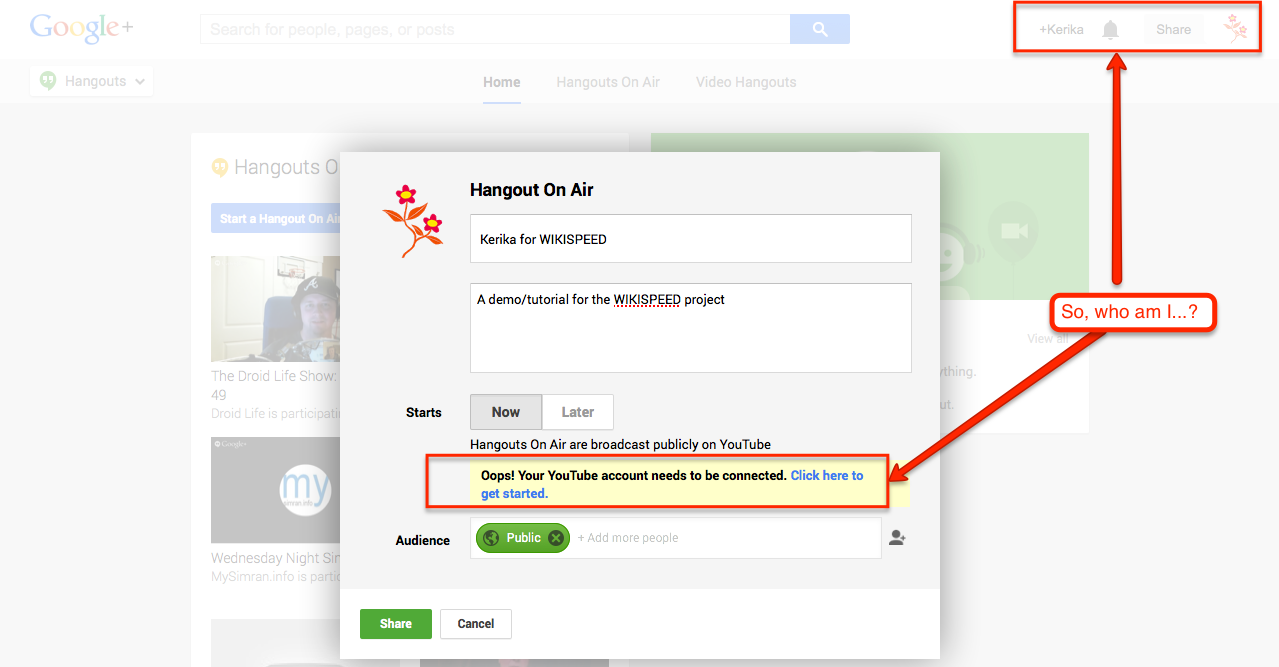
Well, we do have a YouTube channel for info@kerika.com, and Google+ account, also for info@Kerika.com, but that’s not good enough for Google which keeps providing this singularly unhelpful message:
Trying (and failing) to start a Google Hangout
Clicking on the “Click here to get started” link, which you might reasonably expect to take you to a control panel screen of some sort, just takes you down a wild-goose chase of outdated help pages from Google. These help pages have clearly not kept up with UI changes at YouTube, nor even with UI changes on Google+ itself.
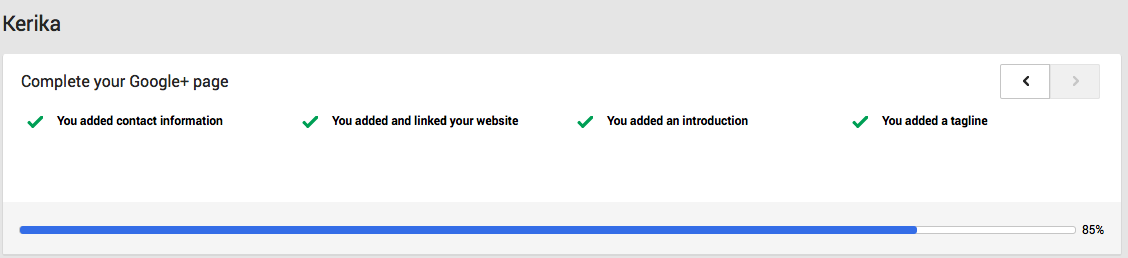
Trying to make sure our Google+ profile is complete doesn’t help either: Google+ tells us that our profile is 85% complete, and that we have done everything we need:
Stuck…
at 85 percent
Pretty painful experience; we are going to stick with GoToMeeting for now.
System that Captures and Tracks Energy Data for Estimating Energy Consumption, Facilitating its Reduction and Offsetting its Associated Emissions in an Automated and Recurring Fashion
Here’s a quick primer on how to delete projects you are no longer working on, and how to retrieve them later from your Trash (think “Recycle Bin” if you are a PC user) if you change your mind.
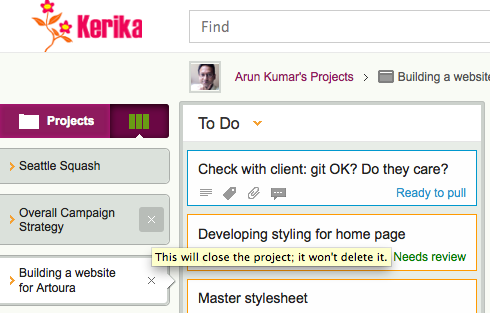
The first point to note is that closing a project is not the same as deleting it: when you are looking at your Boards view, you can have several projects open, each in its own tab. If you hover over any of the project tabs, you will see an “x”: clicking this will close the project.
Closing a project tab
This is a lot like closing a browser tab: it doesn’t kill the website that you were viewing; it just means you are no longer viewing it yourself. In the same way, closing a project tab doesn’t delete the project.
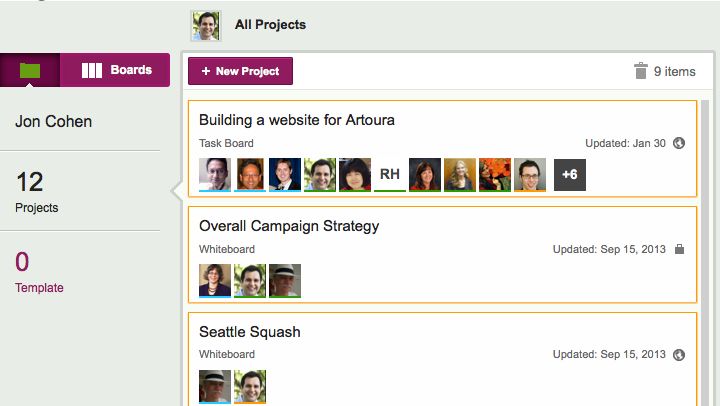
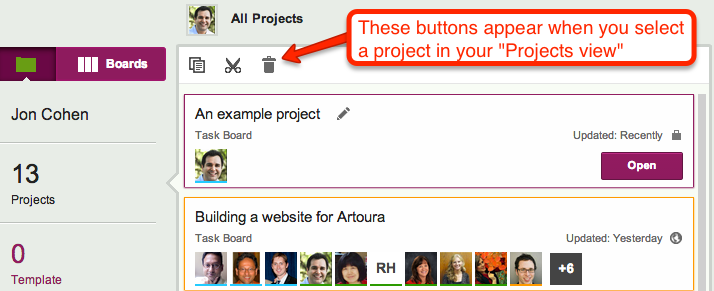
If you actually want to delete a project, click on the “Projects” button, in the top-left corner of the Kerika app (as shown above), and you will see a list of all your projects:
Viewing all your projects
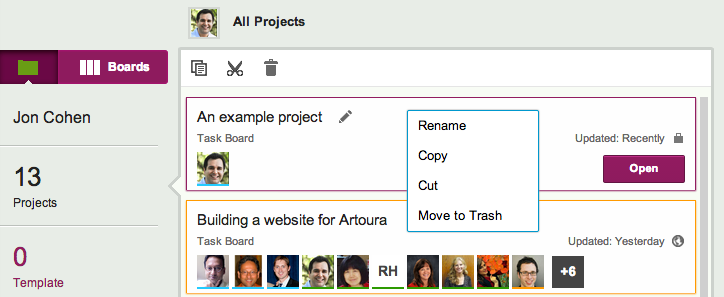
Here, you can select an individual project, and then Cut, Copy, or Delete it:
Project operations
These buttons also appear when you use your right-mouse button, while working on a desktop or laptop:
Right-click menu
If you click on the Trash button (or select “Move to Trash” from the right-click menu), your project will get deleted.
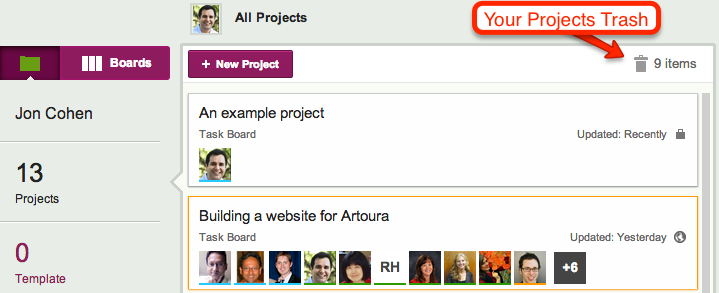
Deleted projects go into a Trash, which is like a Recycle Bin: you can retrieve it later if you change your mind or make a mistake.
The Projects Trash appears just above your list of projects:
Projects Trash, in the Projects View
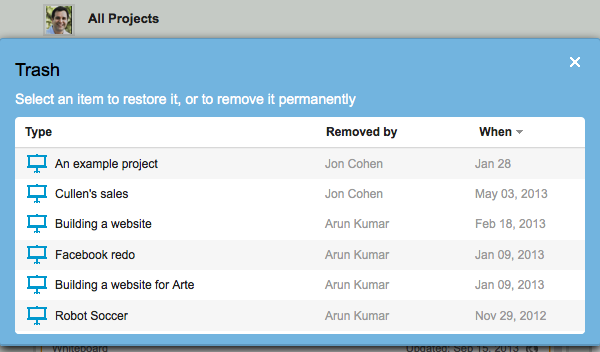
Whenever a project is moved to the Trash, the Project Trash button glows orange, briefly, to alert you. Click on the button and you will see a list of all the projects that are in your Projects Trash:
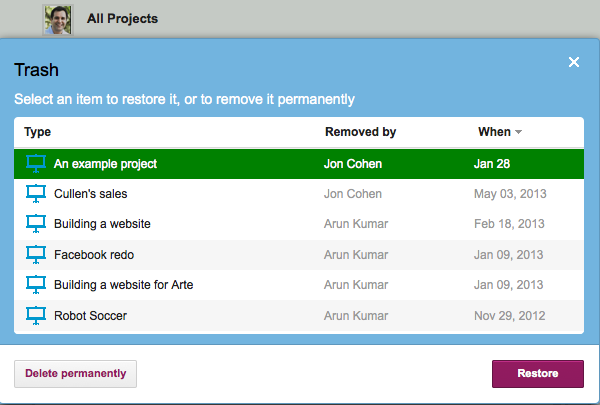
Viewing the Projects Trash
You can now select an individual project, and choose to either restore it, or delete it permanently:
Restoring a project
So, that’s it: a simple way to delete projects, and retrieve them later if you made a mistake.
We are replacing our integration with Google Docs with a “friends of friends” model.
The Background:
For the past 2 years, Kerika has offered an “auto-completion” feature that let you type just a few characters of someone’s name, and then have a list of matching names and emails appear from your Google Docs. It looked like this:
Auto-completion of invitations
This was actually a very helpful feature, but it was also scaring off too many potential users.
The Problem:
When you sign up as a new Kerika user, Google asks whether it is OK for Kerika to “manage your Google Contacts”. This was a ridiculous way to describe our actual integration with Google Contacts, but there wasn’t anything we could do about this authorization screen.
We lost a lot of potential users thanks to this: people who had been burned in the past by unscrupulous app developers who would spam everyone in their address book. So, we concluded that this cool feature was really a liability.
The Solution:
We are abandoning integration with Google Contacts with our latest software update. Existing users are not affected, since they have already authorized Kerika to access their Google Contacts (and are, presumably, comfortable with that decision), but new users will no longer be asked whether it is OK for Kerika to “manage their Google Contacts”.
Instead, we are introducing our own auto-completion of names and email addresses based upon a friends of friends model: if you type in part of a user’s email, Kerika will help you match this against the names of that are part of your extended collaboration network:
People you already work with on projects.
People who work with the people who work with you.
We hope this proves to be a more comfortable fit for our users; do let us know what you think!
A month ago we wrote about how Kerika makes it really easy to spot bottlenecks in a development process – far easier, in our opinion – than relying upon burndown carts.
That blog post noted that the Kerika team itself had been struggling with code reviews as our major bottleneck. Well, we are finally starting to catch up: over the past two days we focused heavily on code reviews and just last night nearly 80 cards got moved to Done!
Jakob Nielsen, of the Nielsen-Norman group, is an old hand at Web usability – a very old hand, indeed, and one whose popularity and influence has waxed and waned over the last two decades.
(Yes, that’s right: Mr. Nielsen has been doing Web usability for 2 decades!)
Kerika founder, Arun Kumar, had the good fortune of meeting Mr. Nielsen in the mid-90s, when he was just embarking upon his career as an independent consultant. The career choice seemed to have come from necessity: Mr. Nielsen has been working in the Advanced Technology Group at Sun Microsystems, and they had recently, with their usual prescience, decided to disband this group entirely leaving Mr. Nielsen unexpected unemployed.
(This was before Sun concluded there was money to be made by re-branding themselves as the “dot in dot com“. As with so many opportunities in their later years, Sun was late to arrive and late to depart that particular party.)
It must have seemed a treacherous time for Mr. Nielsen to embark upon a consulting career in Web usability, back in the mid-90s, when despite Mosaic/Netscape’s success a very large number of big companies still viewed the Internet as a passing fad. And Mr. Nielsen, from the very outset, opposed many of the faddish gimmickry that Web designers, particular Flash designers, indulged in: rotating globes on every page (“we are a global company”, see?) and sliding, flying menus that made for a schizophrenic user experience.
Despite the animus that Flash designers and their ilk have directed towards Mr. Nielsen over the past decade – an animus that is surely ironic given how Flash has been crumbling before HTML5 – his basic research and their accompanying articles have stood the test of time, and are well worth re-reading today.
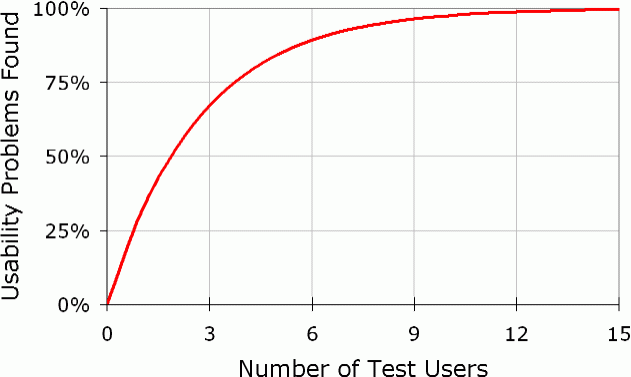
Here’s one that directly matches our own experience:
Elaborate usability tests are a waste of resources. The best results come from testing no more than 5 users and running as many small tests as you can afford.
If you want to get rid of an old Kerika account, the easiest way is to simply de-authorize it from your Google account.
First, some background: when you sign up as a Kerika user, we use Google to figure out who you are, and what your email address is. (And to get permission to put Kerika project files in your Google Drive).
This means that Kerika becomes an authorized app, as far as Google is concerned.
And, it also means that you can de-authorize Kerika any time you want, from your Google account itself. Without authorization, you can’t use your old Kerika account, and neither can anyone else (assuming no one stole your Google password!)
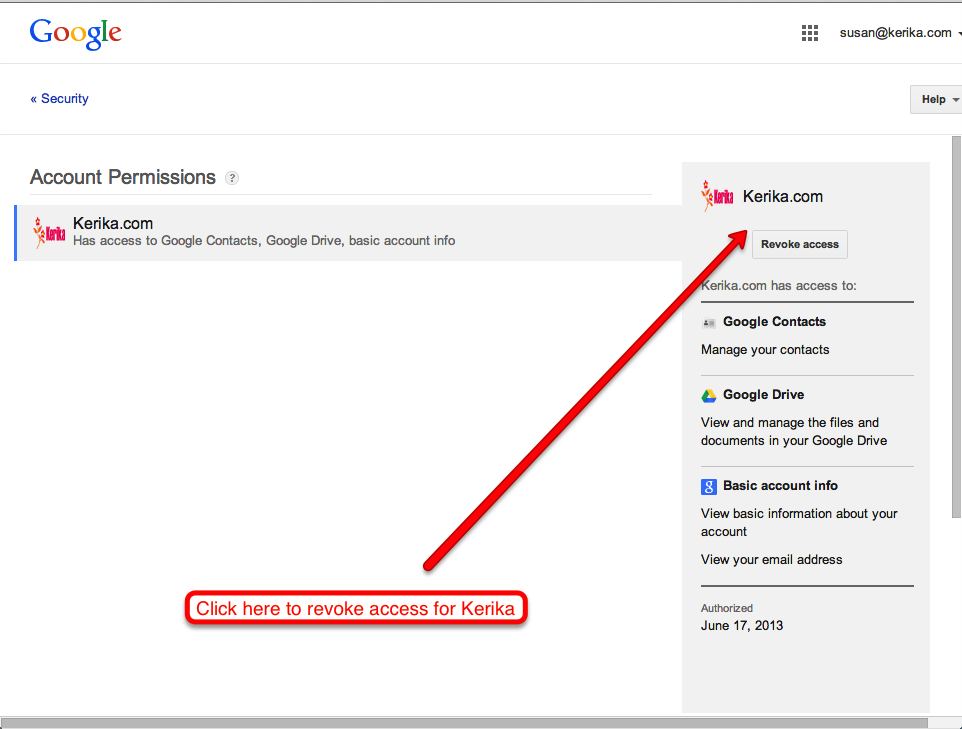
Here, you will all the third-party applications, including Kerika, that are currently authorized to use your Google credentials. Simply Revoke Access to Kerika, and you will disable your Kerika account:
Click here to revoke access for Kerika
Note: you need to make sure you are logged out of Kerika as well. If you leave yourself logged into Kerika on someone else’s computer, they will be able to continue to view your old projects, although they won’t be able to access any of the files that are stored in your Google Drive, or add any new files.
(Updated April 6, 2014 to reflect changes by Google)
If you are going to use Kerika for business, and don’t have a premium Google Apps account, make sure you create a new Google ID that maps to your existing (business) email ID.
For example, if you are someone@somecompany.com, you can create a new Google ID that is “someone@somecompany.com”: it works just like any other Google ID, and it doesn’t require you to switch to Gmail or anything like that.
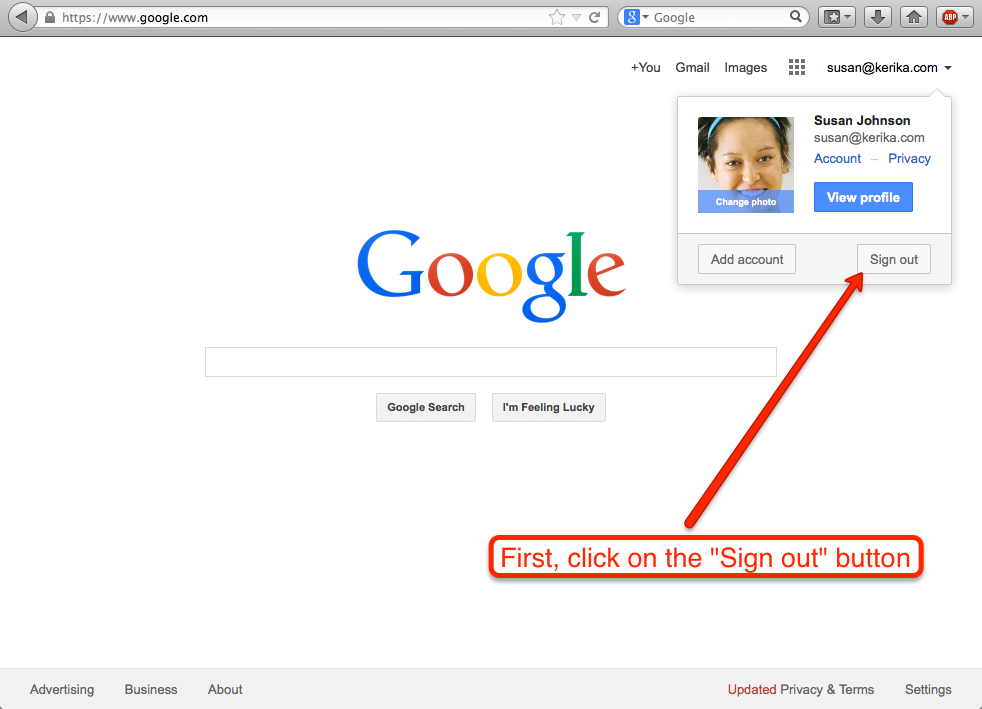
First, sign out of your old Google account:
First, click on the Sign out button
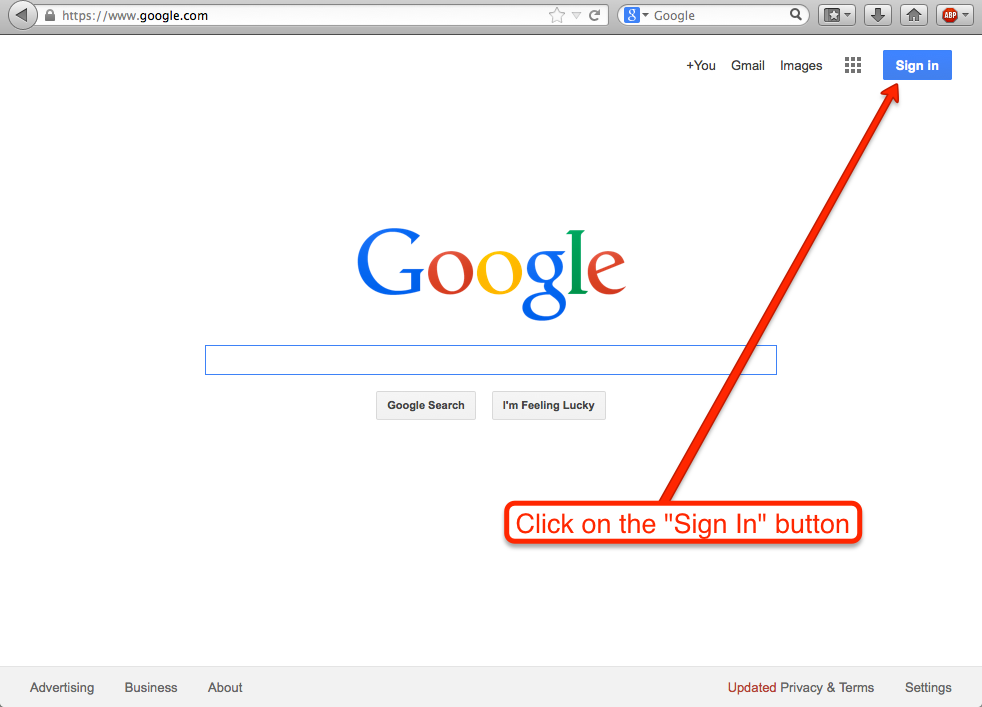
Then, click on the Sign In button at the top-right:
Click on the Sign In button
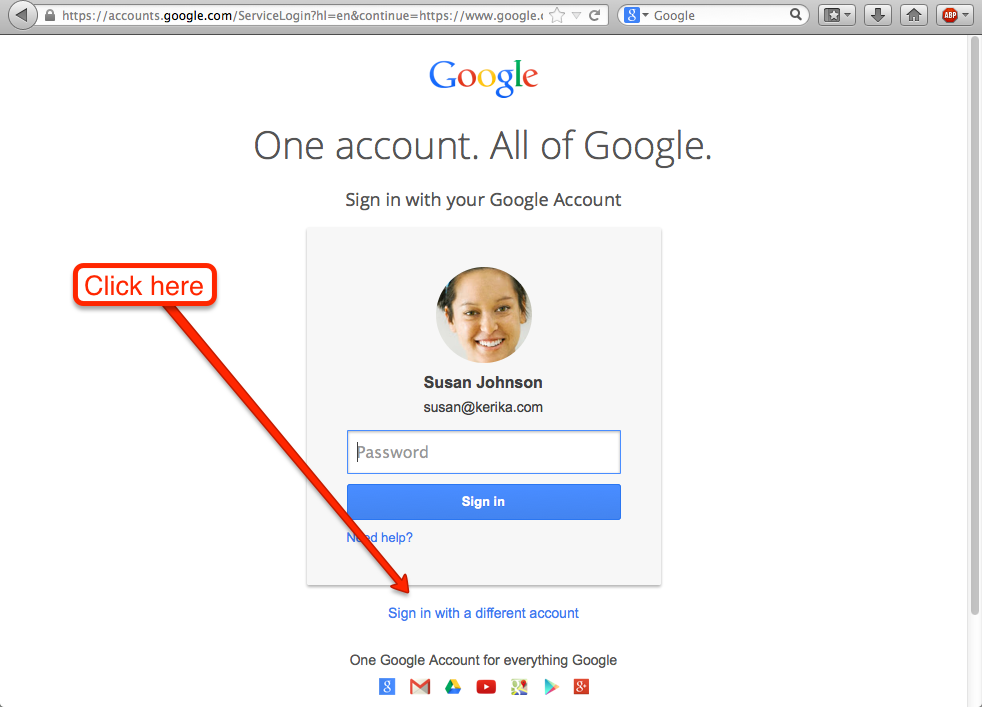
Before you create a new Google ID, you need to make sure you have completely signed out of your old Google ID. To do that, click on Sign in with a different account:
Click on Sign in with a different account
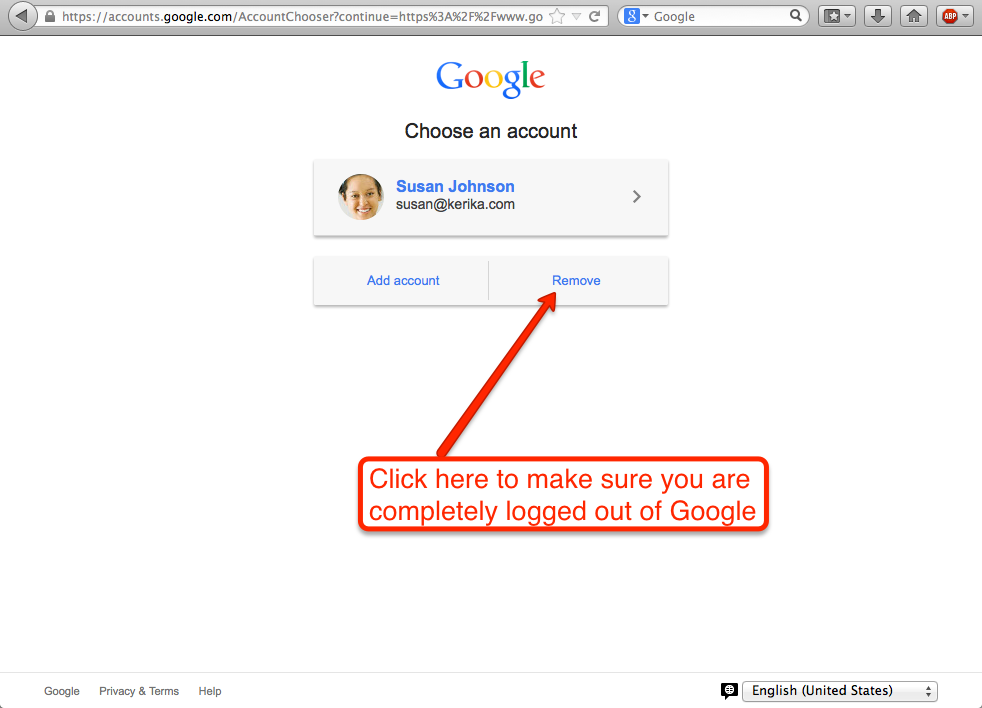
This step is scary-looking (intentionally?), but you need to Remove your account first. This doesn’t mean that you are actually closing or deleting your old Google account, it just means you are finally removing Google’s cookie from your browser.
Click here to make sure you are completely logged out
Clicking on Remove brings up this screen:
Click on the X button
Now you are finally logged out of Google!
Now you are finally logged out of Google
Now, you are ready to set up a new Google account. Click on the Create an account link:
Click here to create a new account
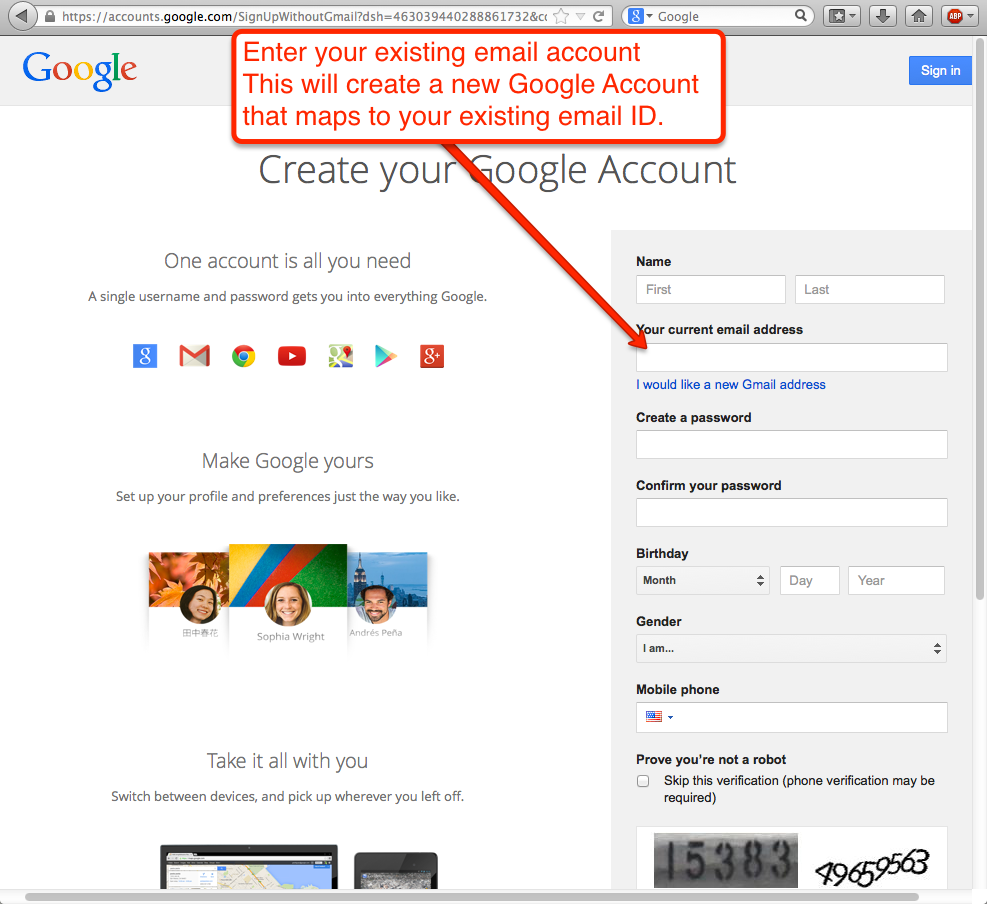
Click on I prefer to use my current email address
Click here to use your existing email account
And, you are finally ready to create a new Google ID, that maps to an existing business email. This could be an email ID from anywhere: you can use a Yahoo email or a Hotmail ID, as well as any email ID from your employer.
Final step
Creating a new Google ID in this way doesn’t mean you are switching to Gmail!
We have been experiencing a CPU spike on one of our servers over the past week, thanks to a batch job that clearly needs some optimization.
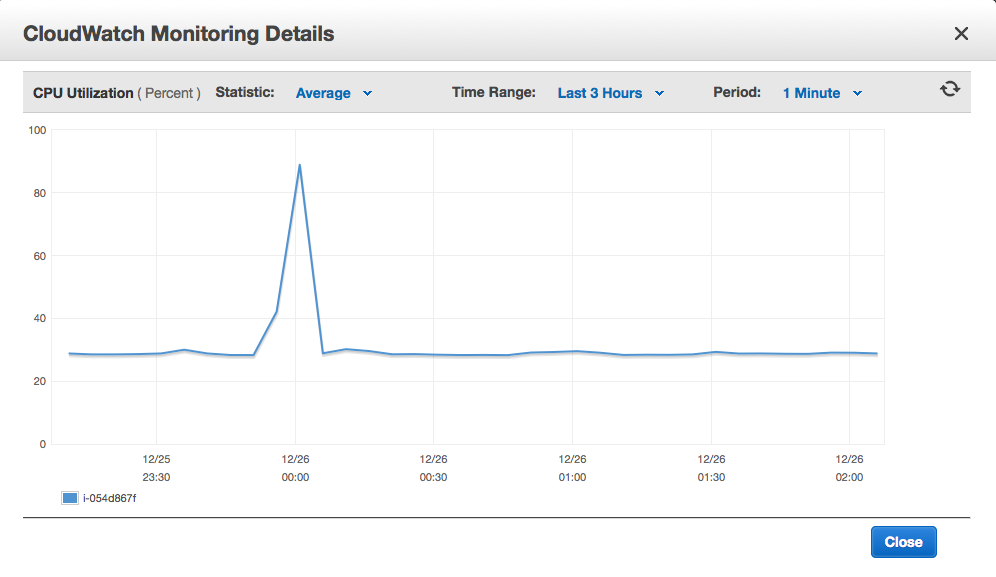
The CPU spike happens at midnight, UTC (basically, Greenwich Mean Time), when the job was running, and it looks like this:
CPU spike
It’s pretty dramatic: our normal CPU utilization is very steady, at less than 30%, and the over a 10-minute period at midnight it shoots up to nearly 90%.
Well, that sucks. We have disabled the batch job and are going to take a closer look at the SQL involved to optimize the code.
Our apologies to users in Australia and New Zealand: this was hitting the middle of their morning use of Kerika and some folks experienced slowdowns as a result.
Talk to old-timers at Microsoft, and they will wax nostalgic about Windows Server 2003, which many of the old hands describe as the best Windows OS ever built. It was launched with over 25,000 known bugs.
Which just goes to show: not all bugs need to be fixed right away.
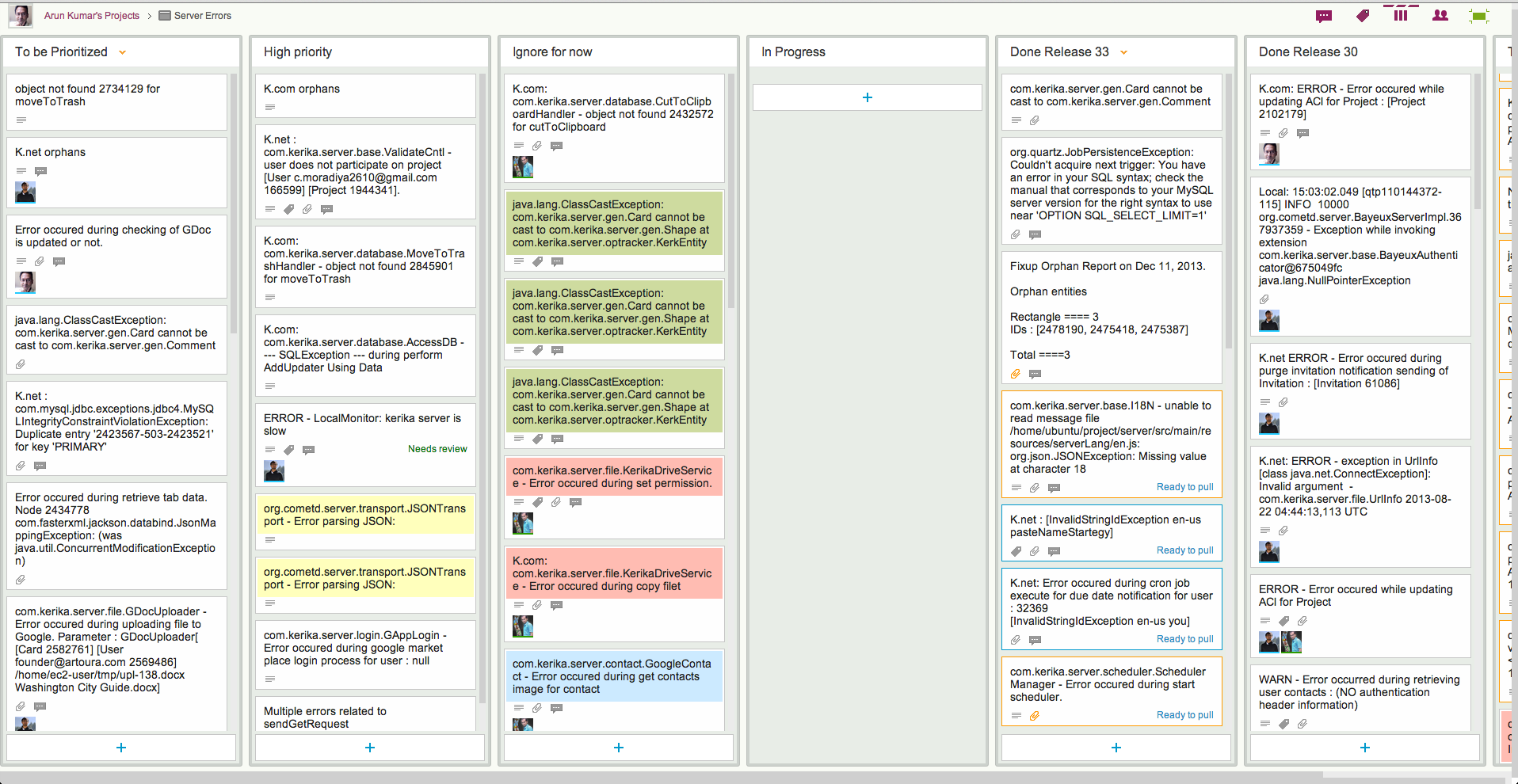
Here at Kerika we have come up with a simple prioritization scheme for bugs; here’s what our board for handling server-related bugs looks like:
How we prioritize errors (click to enlarge)
This particular board only deals with exceptions logged on our servers; these are Java exceptions, so the cards may seem obscure in their titles, but the process by which we handle bugs may nonetheless be of interest to others:
Every new exception goes into a To be Prioritized column as a new card. Typically, the card’s title includes the key element of the bug – in this case, the bit of code that threw the exception – and the card’s details contain the full stack trace.
Sometimes, a single exception may manifest itself with multiple code paths, each with its own stack trace, in which case we gather all these stack traces into a single Google Docs file which is then attached to the card.
With server exceptions, a full stack trace is usually sufficient for debugging purposes, but for UI bugs the card details would contain the steps needed to reproduce the bug (i.e. the “Repro Steps”).
New server exceptions are found essentially randomly, with several exceptions being noted in some days and none in other days.
For this reason, logging the bugs is a separate process from prioritizing them: you wouldn’t want to disturb your developers on a daily basis, by asking them to look at any new exceptions they are found, unless the exceptions point to some obviously serious errors. Most of the time the exceptions are benign, and perhaps annoying, rather than life-threatening, so we ask the developers to examine and prioritize bugs from the To be Prioritized column only as they periodically come up for air after having tackled some bugs.
Each bug is examined and classified as either High Priority or Ignore for Now.
Note that we don’t bother with a Medium Priority, or, worse yet, multiple levels of priorities (e.g. Priority 1, Priority 2, Priority 3…). There really isn’t any point to having more than two buckets in which to place all bugs: it’s either worth fixing soon, or not worth fixing at all.
The rationale for our thinking is simple: if a bug doesn’t result in any significant harm, it can usually be ignored quite safely. We do about 30 cards of new development per week (!), which means we add new features and refactor our existing code at a very rapid rate. In an environment characterized by rapid development, there isn’t any point in chasing after medium- or low-priority bugs because the code could change in ways that make these bugs irrelevant very quickly.
Beyond this simple classification, we also use color coding, sparingly, to highlight related bugs. Color coding is a feature of Kerika, of course, but it is one of those features that needs to be used as little as possible, in order to gain the greatest benefit. A board where every card is color-coded will be a technicolor mess.
In our scheme of color coding, bugs are considered “related” if they are in the same general area of code, which provides an incentive for the developer to fix both bugs at the same time since the biggest cost of fixing a bug is the context switch needed for a developer to dive into some new part of a very large code base. (And we are talking about hundreds of thousands of lines of code that make up Kerika…)
So, that’s the simple methodology we have adopted for tracking, triaging, and fixing bugs.
What’s your approach?
This website uses cookies to improve your experience. We'll assume you're OK with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.