One of our oldest features has outlived it’s usefulness…
(No, we didn’t actually shoot this dog. Or any other dog.)
We have something we call the “Render Server”: it’s a separate server from the rest of Kerika, and it’s sole purpose has been to create thumbnail images of Whiteboard projects.
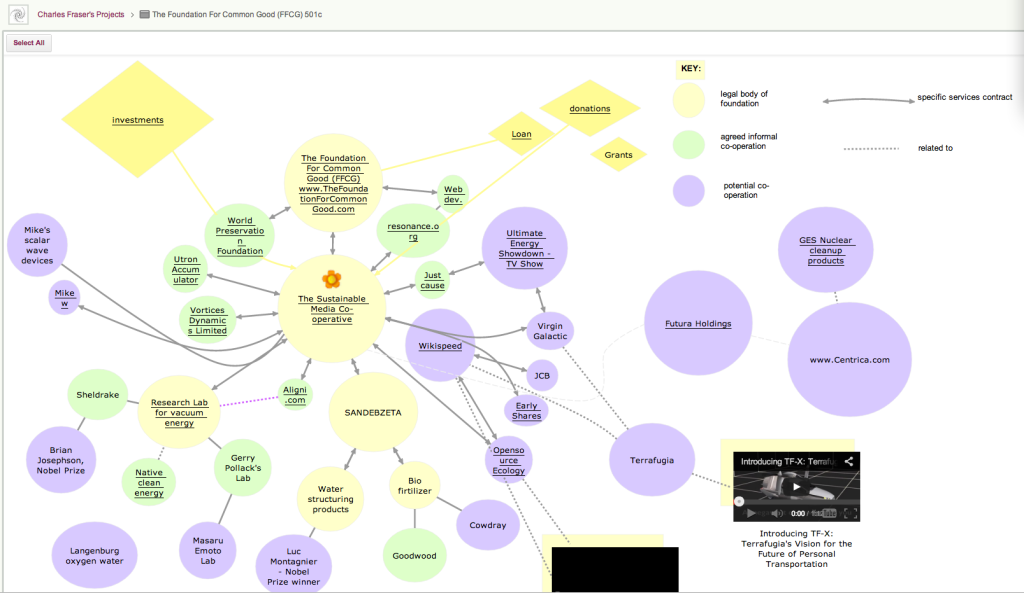
This feature was originally built to make it easier for people who created rich, layered Whiteboards — boards where canvases are contained with other canvases, like the amazing Foundation for Common Good Whiteboard project created by Charles Fraser‘s team (in the UK, and worldwide) which looks something like this:
Foundation for Common Good
This is just a partial view of the top-level of a series of canvases, layered within each other to create a rich, multi-media world.
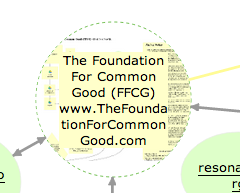
The Render Server helped people understand that some shapes on a canvas contain other canvases within them: for example, if you hovered your mouse over one of the circles on this canvas, you could see — somewhat dimly — a thumbnail of the canvas that was contained within that page:
Showing layered pages
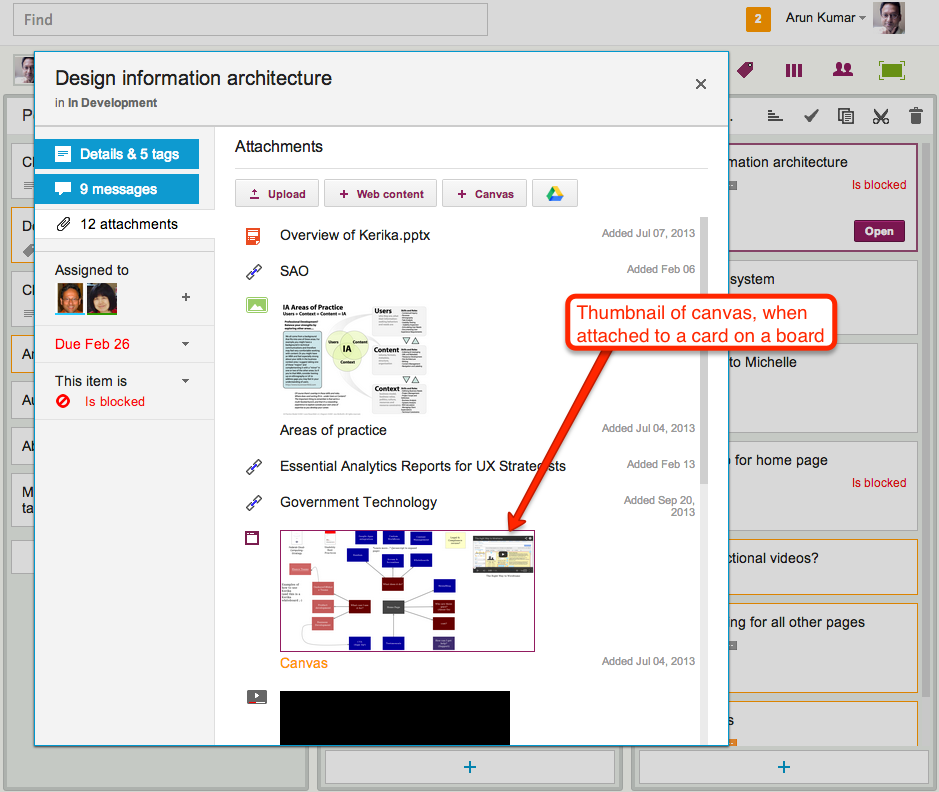
This feature was also used when you added canvases to cards on Task Boards and Scrum Boards: the card details dialog would show a thumbnail of the canvas, like this
Thumbnail image of a canvas attached to a card
This feature was cool, and made for great demos, but it was ultimately not all that useful in a practical sense.
(And that’s true for a lot of cool ideas: things that make for great demos don’t always provide great utility in regular use.)
The thumbnails were too small to be of much use on Whiteboards, and when shown on card details for Task Boards and Scrum Boards they just took up too much space.
So, it’s buh-bye to the Render Server: a cool idea, whose time seems to have passed.
(No, really: we didn’t shoot the dog! We promise!)
Since Kerika is built on top of Google Docs and Google Drive, any problems with Google Apps can affect Kerika.
This doesn’t happen very often, but today Google Apps did suffer an outages, and a total of 14 Kerika users were affected. (We have written to each person affected to apologize!)
This dashboard is a handy way to keep track of the health of Google Apps.
We are often asked to advise our users on workflow: it isn’t a primary business of ours – we prefer to build partnerships with process consultants who can provide great services – but the insights we garner from these brief, often unofficial engagements do heavily influence our product design and roadmap planning.
Recently, we have been helping a large industrial company rethink it how it processes requests that come into its various engineering teams, and as a result reorganize its workflow so that there is optimal flow of work across its various design and engineering teams.
Background:
The company is based in North America, and operates on a 24×7 basis all year around, which isn’t unusual in industries that need continual production in order to fully utilize their very expensive equipment. As a result, their “distributed team challenge” was a little unusual: the teams weren’t distributed by location, but by time.
Every aspect of the companies design and engineering functions – which involved highly specialized teams – needed to be replicated in a day shift and a night shift so that work could be handed off continuously throughout the 24-hour cycle. And, that extended to weekends as well: some folks got a “regular weekend” (i.e. Saturday and Sunday off), while others got “staggered weekends” (e.g. Monday and Tuesday off).
Challenges:
In many respects, these teams had collaboration challenges that match those of a US-India distributed team, e.g. a team based on the US West Coast trying to collaborate with a team based in India, and having to deal with a 12.5-13.5 timezone difference (the variation comes from Daylight Savings Time, which isn’t observed in India.)
This 24×7 challenge was relatively straightforward: we have a lot of experience with helping US-India distributed teams work efficiently – based on our own experience, of course.
A different challenge had to do with streamlining the work of the multiple design and engineering teams involved: work requests were coming in from all directions, some through official channels like project planning meetings, and others through unofficial channels like hallway conversations, and in the absence of a clearly defined process to triage new requests, the various teams were feeling randomized.
All these requests were coming in, unfiltered and without any prior review, into a combined backlog that was being used by multiple teams, each of which would normally work independently, often in parallel with each other, and sometimes sequentially (serially) with each other.
Solution:
The solution we proposed was to create another Kerika board that sat upstream of the main engineering board.
This board was used to capture ideas and triage them, and ensure that only complete, appropriate requests made it to the main board’s backlog. This upstream board also helped divert single-team requests to other boards that were created for handling work items that were not cross-team or cross-functional.
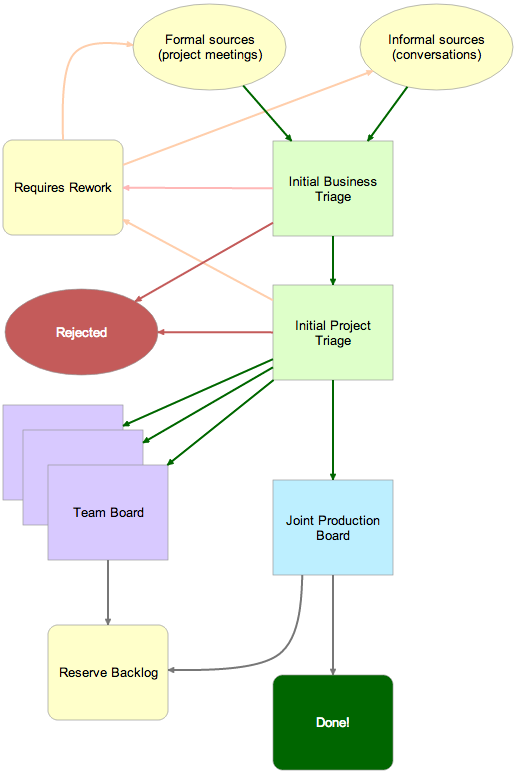
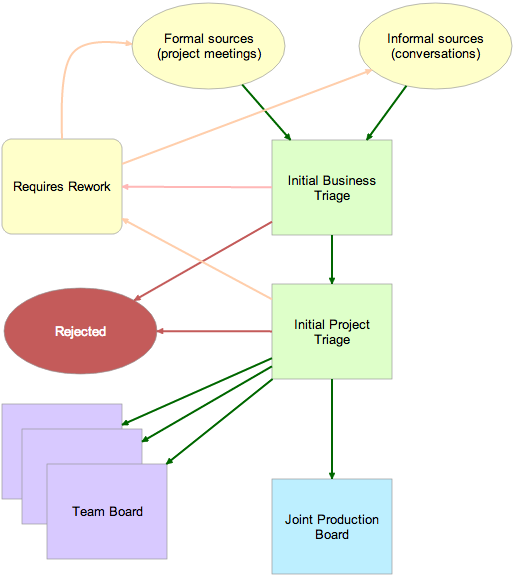
The entire process was captured as a Kerika Whiteboard, as illustrated below:
Workflow for a multi-team industrial company
Let’s take a look at this entire flow, piece by-piece:
At the top, we have requests coming in: formal requests initiated at project planning requests, and informal requests that originated in stray emails, unexpected hallway conversations, etc. All of these are captured as cards on a Planning Board organized with these columns:
New items :: Under Review :: Accepted by Business :: Accepted by Project :: Needs Rework :: Rejected
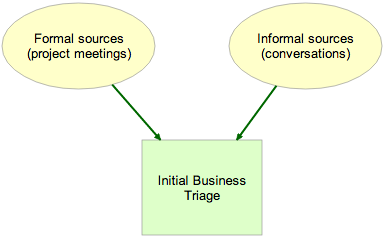
We recommended that a single person be designated as Business Owner, and tasked with doing the initial Business Triage of new cards:
Initial Business Triage
The scope of Initial Business Triage is fairly limited: the Business Owner was asked to examine each new card, on a daily basis, and determine whether it qualified as Accepted by Business, Needs Rework, or Rejected.
Enough new ideas came into the organization that a daily review was recommended, and, importantly, the Business Owner was asked to move cards from New Items to Under Review so that people visiting the board at any time (of the day or night!) could see that their requests were in fact being worked on.
And, equally importantly, people could see the overall volume of requests coming into the organization, and adjust their expectations accordingly as to how promptly their own requests might be processed.
To further emphasize transparency and build support for the engineering teams, we recommended that the Planning Board include as many stakeholders as possible, added to the board as Visitors.
As noted above, the goal was to determine whether a card could be Accepted by Business or not, and for this the card needed:
A sufficiently complete description for the work to be handed off to the engineering teams;
To be within the plant’s overall scope and mission (as with most industrial companies, there were several large plants, each with a distinct mission);
Have budget clearance.
This arrangement helped us achieve two important goals
Encourage the promiscuous sharing of ideas, while simultaneously
Ensuring new ideas met a minimum standard of completenessand relevance.
If an idea was within the organization’s scope/mission, but lacked sufficient detail or the appropriate budget approval, it was marked as Needs Rework. And if an idea was clearly outside scope, or had no chance of being funded, it was Rejected.
Another key consideration was to discourage people from setting Due Dates on cards early in the process: delaying the setting of deadlines, until the work reached the teams that would actually commit to delivery, helped preserve flexibility in scheduling and allocating resources.
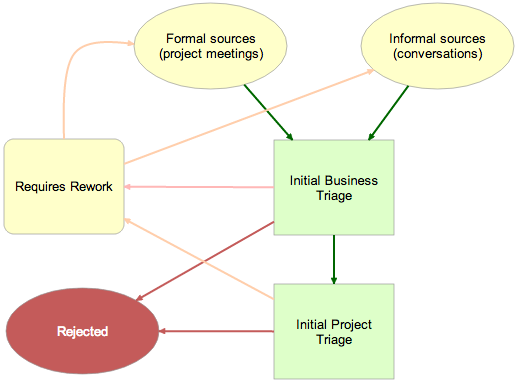
Once the Business Owner did her initial triage of new work, cards were picked up by the designated Project Manager:
Initial PM Triage
The Project Manager worked off the same Planning Board as the Business Owner; she picked up cards that were Accepted for Business. Her goal was to determine the likely impact of each work item, and, critically, to channel the work to either one of the single-team boards, or to the Joint Production board:
Channeling work to the appropriate boards
The Project Manager’s review focused not on business utility (since that was handled earlier by the Business Owner), but rather on identifying whether the work request was likely to affect a single team, or multiple teams.
If the work was likely to affect only a single team, the card was moved to that team’s Kerika board using a simple Cut-Paste operation.
If the work was likely to affect multiple teams, it was moved to the Joint Production Board, which was organized with these columns:
Backlog :: In Progress :: This Week :: Today :: Commission
Tags were used to identify the team involved; since the Joint Production Board typically had hundreds of cards at any point in time, and dozens of team members, this was essential for quick reviews by individual Team Members who wanted to filter out their team’s work items.
As team members became available, they looked first to the Today column to see if anything was marked as Ready to Pull.
If there was nothing in the Today column that was appropriate for the individual person’s skill sets, the person then looked to the This Week column for items that were Ready to Pull.
As an item was taken up by an individual Team Member, she would put her face on the card, to signal to the rest of the team that she had taken ownership of the work.
As work got done, the work product (design documents, engineering plans, etc.) were attached to the cards.
As questions arose, or handoffs were made between team members or entire teams, Kerika’s integrated chat was used to communicate on the cards themselves. (And this is where the 24×7 operation really started to hum!)
Where appropriate Due Dates were set. We had noted earlier that we discouraged people from setting Due Dates at the time they requested new work, to preserve flexibility for the production teams; at this stage it was now appropriate for the teams to make date commitments.
Since all the work that reached the Joint Production Board involved multiple teams (by definition), the card details were updated to reflect the interim deadlines, e.g. the deadline for the Design Team to hand-off something to the Electrical Engineering team.
Once work was completed on a card, it was moved to the Commission column where the final deployment was handled. After that, the card would be moved to Done, and periodically (once a week) the Done column was swept off to another ProjectArchive board.
Occasionally, work would be shunted off to Reserve Backlog: this contained ideas and requests that were plausible or desirable in general terms, but had no realistic chance of being implemented in the short-term.
Workflow for a multi-team industrial company
Key Lessons Learned
Some aspects of this workflow design should be of interest to teams in other industries and sectors:
The use of a Planning Board to act as a way station for ideas and work requests, so that the main boards of the individual teams, as well as the Joint Production Board were not disrupted.
The way station helped ensure that only complete work requests went on to the engineering boards.
The way station encouraged people to contribute ideas and improve them before they were sent to engineering.
Encouraging people to contribute ideas, by making the Planning Board open to a wide group of people who were given Team Member rights (i.e. the ability to add and modify cards).
Separating the roles of Business Owner and Project Manager, so that the business evaluation was distinct from the implementation evaluation.
Separation of individual team boards from the joint production board, so that single-team requests could get processed faster than they would have, if everything had gone through a single pipeline, on a single joint production board.
The user of a Reserve Backlog, to hold on to ideas that the teams might wish to revisit in the future.
What do you think?
We would love to hear your thoughts on this case study!
Global, distributed, agile: words that describe Kerika, and WIKISPEED.
WIKISPEED is a volunteer based green automotive-prototyping company that’s distributed around the world and coming together on a Kerika board to design and build safe, low-cost, ultra-efficient, road-legal vehicles.
We first visited WIKISPEED in the summer of 2012, as part of our research into the needs of distributed, agile teams.
We found huge walls covered with sticky notes:
Dedicated volunteers….
And the irrepressible Mr. Joe Justice himself:
Today, WIKISPEED uses Kerika’s Scrum Boards to organize itself (you can see them at kerika.com/wikispeed):
This transformation has helped knit together folks from around the world: the Kerika boards are now used by WIKISPEED volunteers in the United States, Canada, Europe and New Zealand to communicate and collaborate. A great example of how Kerika can help bring together a globally distributed agile team!
(And, by the way, Kerika was a proud sponsor of the WIKISPEED car that was built for the Future of Flight Aviation Center in Everett, Washington ;-))
System that Captures and Tracks Energy Data for Estimating Energy Consumption, Facilitating its Reduction and Offsetting its Associated Emissions in an Automated and Recurring Fashion
We have been experiencing a CPU spike on one of our servers over the past week, thanks to a batch job that clearly needs some optimization.
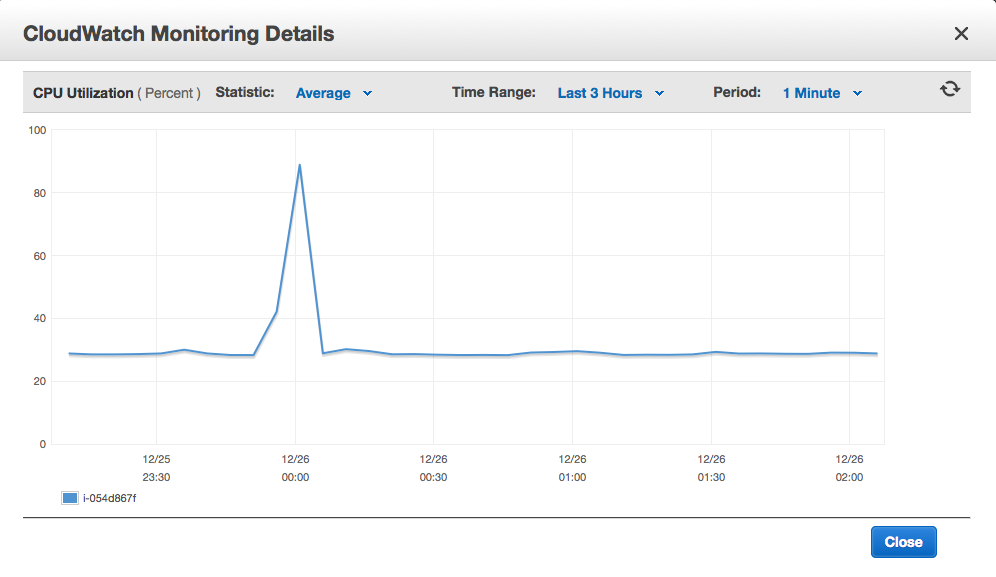
The CPU spike happens at midnight, UTC (basically, Greenwich Mean Time), when the job was running, and it looks like this:
CPU spike
It’s pretty dramatic: our normal CPU utilization is very steady, at less than 30%, and the over a 10-minute period at midnight it shoots up to nearly 90%.
Well, that sucks. We have disabled the batch job and are going to take a closer look at the SQL involved to optimize the code.
Our apologies to users in Australia and New Zealand: this was hitting the middle of their morning use of Kerika and some folks experienced slowdowns as a result.
Talk to old-timers at Microsoft, and they will wax nostalgic about Windows Server 2003, which many of the old hands describe as the best Windows OS ever built. It was launched with over 25,000 known bugs.
Which just goes to show: not all bugs need to be fixed right away.
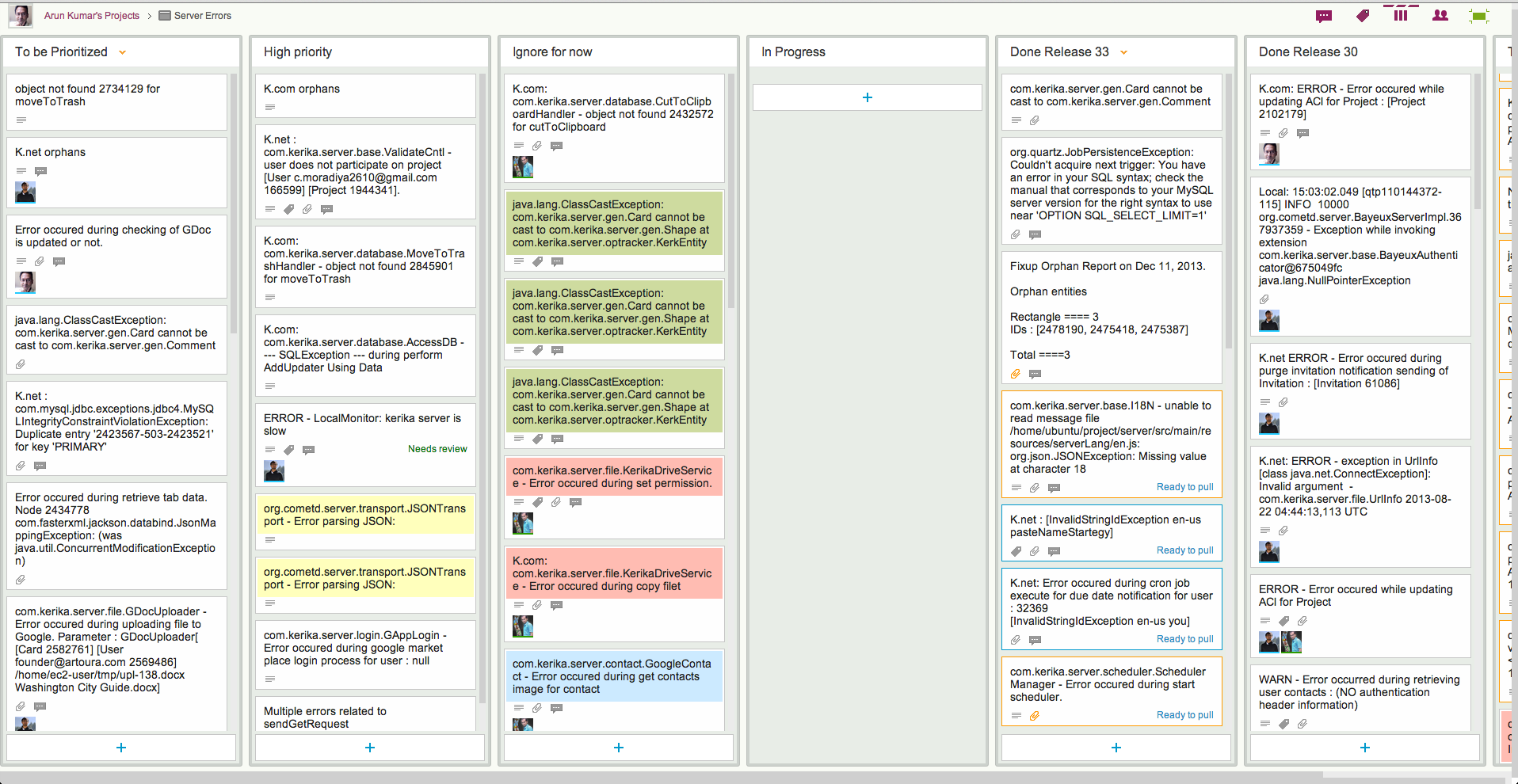
Here at Kerika we have come up with a simple prioritization scheme for bugs; here’s what our board for handling server-related bugs looks like:
How we prioritize errors (click to enlarge)
This particular board only deals with exceptions logged on our servers; these are Java exceptions, so the cards may seem obscure in their titles, but the process by which we handle bugs may nonetheless be of interest to others:
Every new exception goes into a To be Prioritized column as a new card. Typically, the card’s title includes the key element of the bug – in this case, the bit of code that threw the exception – and the card’s details contain the full stack trace.
Sometimes, a single exception may manifest itself with multiple code paths, each with its own stack trace, in which case we gather all these stack traces into a single Google Docs file which is then attached to the card.
With server exceptions, a full stack trace is usually sufficient for debugging purposes, but for UI bugs the card details would contain the steps needed to reproduce the bug (i.e. the “Repro Steps”).
New server exceptions are found essentially randomly, with several exceptions being noted in some days and none in other days.
For this reason, logging the bugs is a separate process from prioritizing them: you wouldn’t want to disturb your developers on a daily basis, by asking them to look at any new exceptions they are found, unless the exceptions point to some obviously serious errors. Most of the time the exceptions are benign, and perhaps annoying, rather than life-threatening, so we ask the developers to examine and prioritize bugs from the To be Prioritized column only as they periodically come up for air after having tackled some bugs.
Each bug is examined and classified as either High Priority or Ignore for Now.
Note that we don’t bother with a Medium Priority, or, worse yet, multiple levels of priorities (e.g. Priority 1, Priority 2, Priority 3…). There really isn’t any point to having more than two buckets in which to place all bugs: it’s either worth fixing soon, or not worth fixing at all.
The rationale for our thinking is simple: if a bug doesn’t result in any significant harm, it can usually be ignored quite safely. We do about 30 cards of new development per week (!), which means we add new features and refactor our existing code at a very rapid rate. In an environment characterized by rapid development, there isn’t any point in chasing after medium- or low-priority bugs because the code could change in ways that make these bugs irrelevant very quickly.
Beyond this simple classification, we also use color coding, sparingly, to highlight related bugs. Color coding is a feature of Kerika, of course, but it is one of those features that needs to be used as little as possible, in order to gain the greatest benefit. A board where every card is color-coded will be a technicolor mess.
In our scheme of color coding, bugs are considered “related” if they are in the same general area of code, which provides an incentive for the developer to fix both bugs at the same time since the biggest cost of fixing a bug is the context switch needed for a developer to dive into some new part of a very large code base. (And we are talking about hundreds of thousands of lines of code that make up Kerika…)
So, that’s the simple methodology we have adopted for tracking, triaging, and fixing bugs.
One great advantage of a visual task board like Kerika is that it is a really fast and easy way to identify bottlenecks in your workflow, far better than relying upon burndown charts.
Here are a couple of real-life examples:
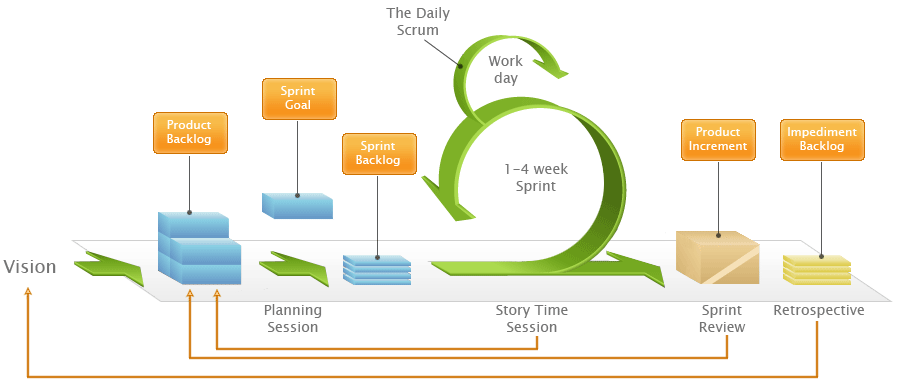
Release 33 and Release 34 are both Scrum iterations, known as “Sprints”.
How Scrum works
Both iterations take work items from a shared Backlog – which, by the way, is really easy to set up with Kerika, unlike with some other task boards 😉 And for folks not familiar with Scrum, here’s a handy way to understand how Scrum iterations progressively get through a backlog of work items:
We could rely upon burndown charts to track progress, but the visual nature of Kerika makes it easy to identify where the bottlenecks are:
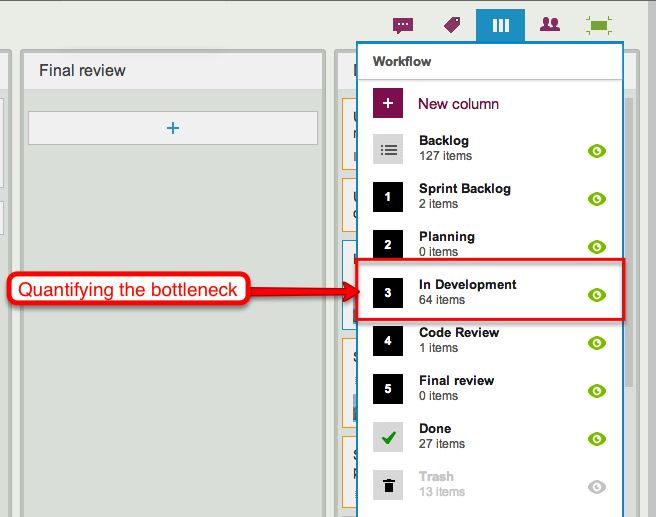
In Release 33, the bottleneck is obviously within the Development phase of the project:
Release 33: a bottleneck in Development
When we take a look at the Workflow display, it’s easy to quantify the problem:
Quantifying the bottleneck in Release 33
By way of contrast, here’s Release 34, another Scrum iteration that’s working off the same Backlog:
Release 34: a smaller bottleneck
This iteration doesn’t have the same bottleneck as Release 33, but warning signs are clear: if we can’t get our code reviews done fast enough, this version, too, will have a develop a crunch as more development gets completed but ends up waiting for code reviews.
In both cases, Kerika makes it easy to see at a glance where the bottleneck is, and that’s a critical advantage of visual task boards over traditional Scrum tools.
A question we are asked fairly often: where exactly is my Kerika data stored?
The answer: some of it is in Amazon Web Services, some of it is in your Google Drive.
Here are the details: your Kerika world consists of a bunch of data, some of which relate to your account or identity, and some relate to specific projects and templates.
Your account information includes:
Your name and email address: theseare stored in aMySQL database on an Amazon EC2 virtual server.Note: this isn’t a private server (that’s something we are working on for the future!); instead, access is tightly controlled by a system of permissions or Access Control Lists.
Your photo and personalized account logo, if you provided these: these are stored in Amazon’s S3 cloud storage service.These are what we call “static data”: they don’t change very often. If you have a photo associated with your Google ID, we get that from Google – along with your name and email address – at the time you sign up as a Kerika user, but you can always change your photo by going to your Kerika preferences page.
Then, there’s all the information about which projects and templates you have in your account: this information is also stored in the MySQL database on EC2.
There are projects that you create in your own account,
There are projects that other people (that you authorize) create in your account,
There are projects that you create in other people’s accounts.
And, similarly, there are templates that you create in your own account or in other people’s accounts.
Within each project or template you will always have a specified role: as Account Owner, Project Leader, Team Member or Visitor – Kerika tracks all that, so we make sure that you can view and/or modify only those items to which you have been given access.
In Task Boards and Scrum Boards, work is organized using cards, which in turn could contain attachments including canvases.
In Whiteboards, ideas and content are organized on flexible canvases, which can be nested inside each other.
With Whiteboards, and canvases attached to cards on Task Boards and Scrum Boards, all the data are stored in MySQL.
With cards on Task Boards and Scrum Boards:
Files attached to cards are stored in your Google Drive,
The title, description, URLs, tags, people and dates are stored in MySQL,
Card history is stored in a Dynamo database on AWS.
So, our main database is MySQL, but we also use Dynamo as a NoSQL database to store history, and that’s because history data are different from all other data pertaining to cards and projects:
The volume of history is essentially unpredictable, and often very large for long-living or very active projects.
History data are a continuous stream of updates; they aren’t really attributes in the sense of relational data.
History data is accessed infrequently, and then it is viewed all at once (again, an aspect of being a continuous stream rather than attributes).
It’s also important to note what we don’t store:
We never store your password; we never even see it because of the way we interact with Google (using OAuth 2.0)
We never store your credit card information; we don’t see that either because we hand you off to Google Wallet for payment.
We have been busy building a great new Search function: the old search worked only with whiteboards, but the new search indexes absolutely everything inside Kerika: cards, chat, attachments – the whole lot.
We will talk about Search in a separate blog post; this article is about the detour we made into Amazon Web Services (AWS) along the way…
Now, we have always used AWS: the Kerika server runs on an EC2 machine (with Linux, MySQL and Jetty as part of our core infrastructure), and we also use Amazon’s Dynamo Database for storing card history – and our use of various databases, too, deserves its own blog post.
We also use Amazon’s S3 cloud storage, but in a limited way: today, only some static data, like account logos and user photos are stored there.
The new Search feature, like our old one, is built using the marvelous Solr platform, which is, in our view, one of the best enterprise search engines available. And, as is standard for all new features that we build, the first thing we did with our new Search function was use it extensively in-house as part of our final usability testing. We do this for absolutely every single thing we build: we use Kerika to build Kerika, and we function as a high-performing distributed, agile team!
Sometimes we build stuff that we don’t like, and we throw it away… That happens every so often: we hate it when it does, because it means a week or so of wasted effort, but we also really like the fact that we killed off a sub-standard feature instead of foisting crapware on our users. (Yes, that, too, deserves its own blog post…)
But our new Search is different: we absolutely loved it! And that got us worried about what might happen if others liked it as much: search can be a CPU and memory intensive operation, and we became worried that if our Search was so good that people started using it too much, it might kill the performance of the main server.
So, we decided to put our Solr engine on a separate server, still within AWS. To make this secure, however, we needed to create a Virtual Private Cloud (VPC) so that all the communications between our Jetty server and our Solr server takes place on a subnet, using local IP references like 10.0.0.1 which cannot be accessed by people outside the VPC. This makes it impossible for anyone outside the VPC to directly access the Solr server, adding an important layer of security.
To communicate between the Jetty server and the Solr server, we have started using Amazon’s Simple Queue Service (SQS).
OK, that means we add VPC to our suite of AWS services, but this started triggering a wider review of whether we should use more AWS services than we currently do. One sore point of late had been our monitoring of the main server: our homemade monitoring software had failed to detect a brief outage (15 minutes total, which apparently no one except our CEO noticed :0) and it was clear that we needed something more robust.
That got us looking at Amazon’s CloudWatch which can be used with Amazon’s Elastic Load Balancer (EBS) to get more reliable monitoring of CPU thresholds and other critical alerts. (And, along the way, we found and fixed the bug which caused the brief outage: our custom Jetty configuration files were buggy, so we dumped them in favor of a standard configuration which immediately brought CPU utilization down from a stratospheric level to something more normal.)
We didn’t stop there: we also decided to use Amazon’s Route 53 DNS service, which provides greater flexibility for managing subnets than our old DNS.
In summary, we have greatly expanded our Amazon footprint:
EC2 for our main Web servers, running Linux, Jetty, MySQL, with separate servers for Solr.
S3 for basic storage.
Dynamo for history storage.
VPC for creating a subnet.
SQS for monitoring.
CloudWatch for monitoring.
Elastic Load Balancer for connecting to servers.
Route 53 for DNS.
Something from Amazon that we did abandon: we had been using their version of Linux; we are switching in favor of Ubuntu since that matches our development environment. When we were trying to debug the outage caused by the high CPU utilization, one unknown factor was how Amazon’s Linux works, and we decided it was an unknown that we could live without:
First of all, why is there an Amazon Linux in the first place, as in: why did Amazon feel they need to make their own Linux distribution? Presumably, this dates back to the very early days of AWS. But is there any good reason to have a vendor-specific Linux distribution today? Not as far as we can tell…
It just adds unnecessary complexity: we are not Linux experts, and have no interest in examining the fine print to determine how exactly Amazon’s Linux might vary from Ubuntu.
Unless you have in-house Linux experts, you, too, would be better off going with a well-regarded, “industry-standard” (yes, we know there’s no such thing in absolute terms but Ubuntu comes pretty close) version of Linux than dealing with any quirks that might exist within Amazon’s variant. When you are trying to chase down mysterious problems like high CPU utilization, the last thing you want is to have to examine the operating system itself!
What we continue to use from Google:
Google login and restriction, based upon OAuth 2.0,
Google Drive for storing user’s local files.
All the pieces are coming in place now, and we should be able to release our new Search feature in a day or two!
This website uses cookies to improve your experience. We'll assume you're OK with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.