(The seventh in a series of blog posts on why we are adding integration with Box, as an alternative to our old integration with Google Drive.)
Having decided to add a second cloud platform, we had to go about the cumbersome, risky process of disentangling Kerika from its close embrace of the Google stack.
This has taken us several months, if we are honest about counting the entire effort and duration.
The first part of this was to create a more layered architecture: wherever there was a direct interface to a Google service, we had to create an intermediate shim that allow us to substitute the Google service with another.
And to be frank, when we first started work on Kerika in 2010, we hadn’t seriously considered the possibility that we would use any other cloud service so our architecture had become, over the years, more Google-focused than we had realized.
Disentangling from Google Contacts was the easiest step, and in fact we had already taken that break some time ago in response to users being fearful about Kerika accessing their Google Contacts.
In terms of login, however, things got much more complicated: we had originally integrated with Google using OAuth 1.0, and then later upgraded to OAuth 2.0 as OAuth 1.0 started to get deprecated.
In theory this meant that we could easily integrate with any other OAuth provider, e.g. Box, Facebook, Yahoo, etc.
But as we developed our long-term strategy and talked to prospective customers, it became clear that sooner or later Kerika would have to provide direct signup/sign-in, in addition to OAuth: a significant contingent of folks wanted to be able to sign up directly at Kerika.com rather than use existing credentials from Google, Box, etc.
(We are not quite sure why this is really advantageous for anyone, but the sentiment is real nonetheless.)
So, we decided to implement our own OAuth server, which would act as a gateway to OAuth servers from Google or Box.
This had to be implemented such that the entire sign-up and sign-in process remains unchanged: someone coming to Kerika.com would get redirected automatically to the correct authentication service, which could then redirect the user’s browser back to the Kerika application server.
And, obviously, the entire process had to be smooth, fast and completely transparent to the end-user: how we implemented multiple OAuth sign-ins wasn’t the user’s concern! This had to work really well for both free users of Google, e.g. folks with just a regular Gmail account, and premium users who had signed up for Google Apps for Business or any of its variants (for Government, Education, and Nonprofits).
Fortunately, we already gained experience in dealing with the complexities of browser redirects in enterprise environments, where any sloppiness in terms of using HTTPS, for example, can trip up security alarms in large organizations.
And, we had learned the hard way to look for various edge cases, like restricted domains — if someone from within a restricted domain tries to add someone from outside that domain, we need to trap that condition so that the user experience remains excellent, rather than landing anyone on some scary error page from Google!
The other major complexity was to normalize the service we provide, so that the user experience is equivalent for both Google and Box users.
An example of a “normalized user experience”: an existing Kerika, who uses Google Drive, decides to invite someone to join a project. At that time, we need to check whether the invitee is already registered as a Kerika user or not. If the invitee is already a Kerika user, we need to see whether that user is also using Google Drive.
If it turns out that the invitee has been using Box, we need to make sure the invitee is correctly prompted to switch from using a Google-based Kerika account to a Box-based account, so that she has all the proper access to the new project’s files. And this switch between accounts needs to be a single-click, to keep the Kerika user experience excellent!
Other examples: exceptions and error conditions as reported by Google and Box are very different, reflecting the peculiarities of each service. We need to make sure we capture all these and try to keep the end-user experience as smooth as possible. Fortunately, we had developed a great deal of experience managing exceptions generated by Google Apps, so we could bring all this to bear on our Box implementation.
To get all this right, we had to carefully plan a series of milestone releases that were done in parallel with our regular development: although the work was going to take several months to finish, we needed to keep supporting our existing users with critical updates, bug fixes and limited new product enhancements.
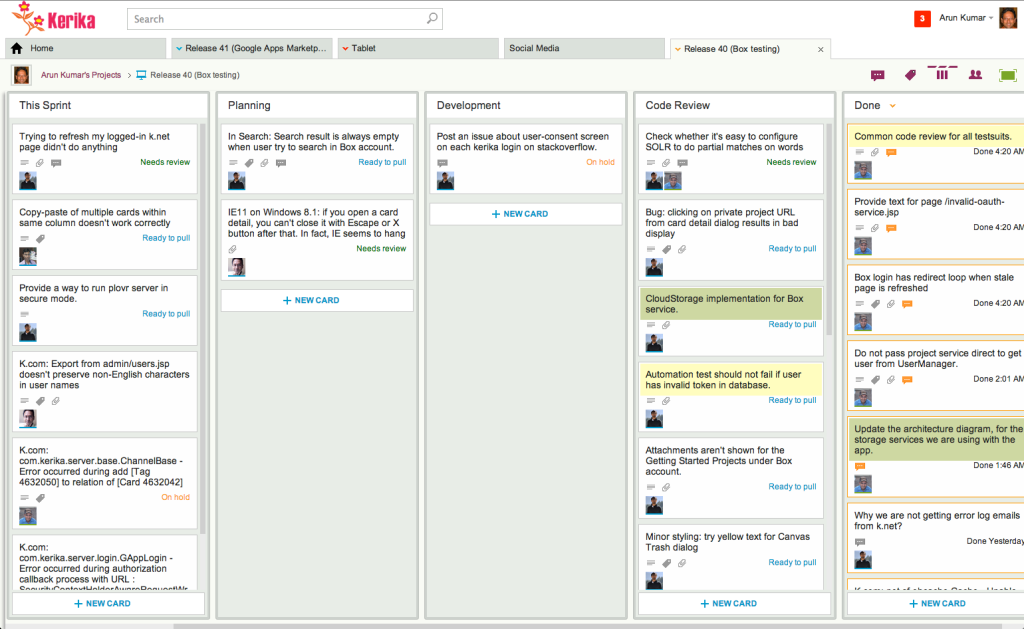
Fortunately Kerika lets you have multiple Scrum Backlogs in the same account, and that’s what we did: we created a separate, smaller Product Backlog consisting of just the OAuth work, and let that development run in parallel while we continued to draw down on our Main Product Backlog.
The OAuth work finally got done in four Sprints, each of which was organized as a separate Scrum Board.
As we came to our regular release cycles, we would pick up items that were complete, from either the OAuth Backlog or the Main Backlog, and merge these to create a new release package.
To get this right, we used git to the fullest, putting each feature into a separate branch so that we could retain the maximum flexibility in terms of what made it into a particular release.
Without this use of multiple git branches, our release cadence would have been tough to maintain.
The full series: