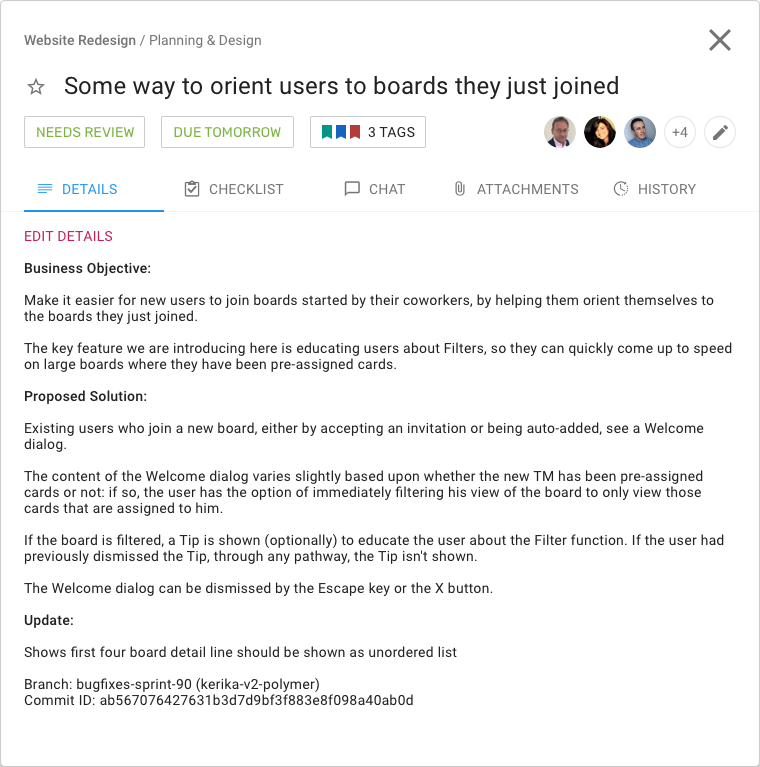
We have made some improvements to the process that guides new users when they sign up, so they can join the accounts of coworkers they might need to work with.
The new process works like this:
When a user signs in (with a Google ID, Box ID, or their email), Kerika examines the email address associated with that user and compares it against other users who are already registered.
If it finds that other users from the same domain are already active Kerika users, it offers the new user the option of joining a colleague’s account or starting an entirely new account.
In most cases, people are better off joining accounts that have already been established by their coworkers, so they can find the most relevant Kerika boards.
Kerika tries to be smart about this in a couple of ways:
First, it rules out free domains, like Gmail, Yahoo, and Outlook. (There’s a long list of free domains that we check against.) With free domains, there could be thousands of other users who have similar emails but no connection with you.
So if you sign up with a free email, you won’t be offered the possibility of joining an existing account. (Of course, an existing Gmail user could invite you to join their teams; it’s just that Kerika doesn’t suggest these connections.)
Having winnowed out the free domains, Kerika then considers whether the older accounts from the same domain as the new user can actually accommodate new people: do they have free subscriptions available that could be used by the new user?
If the older accounts are still in the Free Trial phase, then the answer will be Yes: trial users can have unlimited Team Members .
If the older accounts are tagged as Academic/Nonprofit, there’s a good chance they can accommodate new users.
If the older accounts are Professional Accounts, the chances are much lower — unless the older account had bought a few extra subscriptions in advance to accommodate this scenario.
Having further narrowed down the list of potential accounts, Kerika considers whether your potential coworkers are, in fact, active users of Kerika. This is important in universities, for example, that have been whitelisted so that everyone joining up from a particular university automatically gets a free Academic Account.
From University of Washington, for example, there are thousands of registered free accounts, set up over the past several years. Not all are still active because the students involved may have graduated already. So even though an account may have free/unused subscriptions, it doesn’t make sense to suggest that to a new user if that account has been dormant for more than a month.
After all this we could still end up with a large set of potential list of collaborators, particularly in large organizations.
So, as the final step, we check the “last active time” of our candidate accounts and then present the 8 most recently active accounts. Our rationale is that a new user may want to join the most recently active account, which perhaps belongs to a fellow user who had suggested the new user sign up for Kerika.
All of this takes place in a fraction of a second, of course, so users don’t experience any wait times. But it helps new users orient themselves within Kerika by trying to connect them to the most likely coworkers.