For our extensive redesign of Kerika we used the Sketch design app for the first time, transitioning way from our earlier use of Adobe’s Creative Suite.
Here’s our design effort, by the numbers:
We created a total of 937 individual screen layouts, all of which were high-resolution and pixel-perfect.
Each screen was designed for 1680×1050 pixels, which is the resolution of a 21″ desktop monitor although each design was subsequently tested on a 1400×800 laptop screen as well.
Every element on every screen was laid out to its precise final size and spacing, to create a photo-realistic view of the design.
We exclusively used vector graphics so we could scale our views for different devices and resolutions without any loss of resolution.
Every screen was mocked using real data, rather than lorem ipsum-style fake text, so we could get a more realistic idea of how much space actual cards, columns, etc. would take.
We used realistic storylines for all scenarios: user personas were developed and used consistently, so that, for example, the same person appeared as Board Admin on all screens.
Every interaction between different features was considered simultaneously, so that we could guard against edge cases where the design might clash or fail when multiple user conditions were true at the same time.
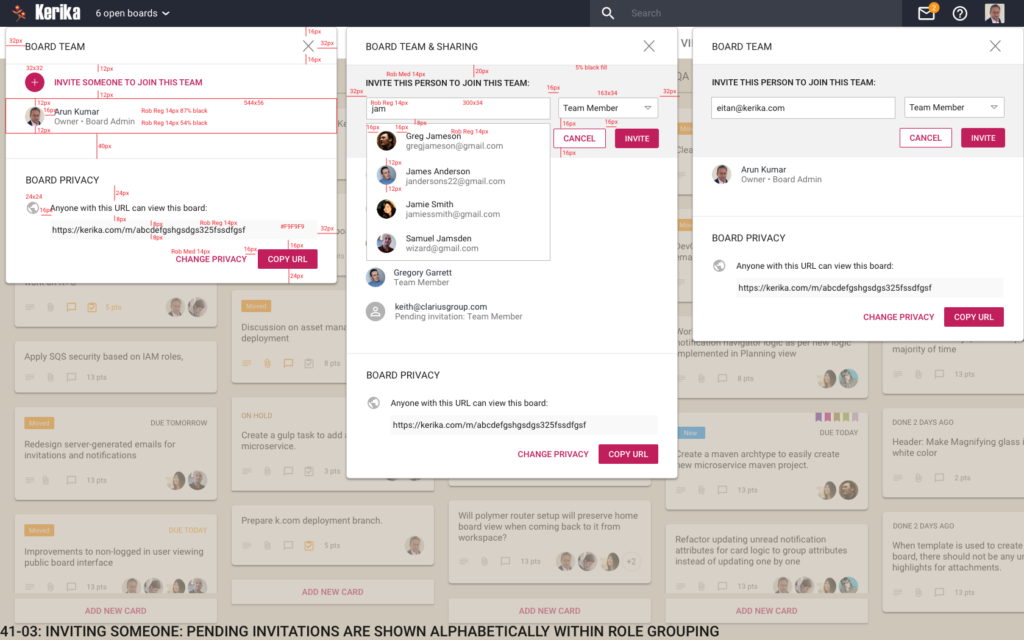
Here’s an example of a screen mockup:
Inviting someone
Here’s the same screen design, with dimensions marked as redlines:
Inviting someone (Markup)
Extensive use of symbols (repeating objects in Sketch) helped us ensure that we had consistency across all 937 designs, simultaneously.
We exported our icons using the Scalable Vector Graphics (SVG) format, rather than PNG or JPEG, to ensure there was no loss of resolution when we used these icons in the Kerika app.
Over 1.5 years, we went through 35 complete iterations of the design, where nearly all 937 screens were changed as we explored different concepts.
Arun Kumar, CEO of Kerika, and Joy Paulus, Senior Policy and Program Manager for the Washington State Office of the CIO, delivered a joint presentation at the Lean Transformation 2016 Conference.
The subject of the talk was “Collaboration Across Organizations: Big Results with Small Teams”. Here are the slides from the talk:
We switched over to Google as the registrar for a number of our domains yesterday (we used to use a mix of GoDaddy and Register.com previously), and in the process our DNS got screwed up.
We didn’t realize this right away because it affected one of our subdomains (which meant the website itself was up and running, but one of the ways in which you can sign into Kerika was messed up.)
The basic problem was with Google’s way of handling incoming transfers of domains that have already been set up: even if you use the setting for keeping your current domains, Google doesn’t keep your current DNS settings for all the subdomains as well.
Our apologies for everyone affected by this!
Update on 10:15AM PST Oct 6:
We are still waiting for Google’s bazillion DNS servers to all get the new DNS entries. It’s a bit hit-or-miss for individual users, depending upon which Google server they get routed to when they try to login.
Here in the Seattle area, for example, we can login consistently, but we know some of our users can’t. In India it is literally a 50:50 chance that your Kerika session will connect to an updated DNS server or not. In the UK the problem seems mostly fixed now.
Interested in using Kerika for software development? Here’s a practical example, taken from one of our own boards, that highlights best practices for tracking, investigating and fixing bugs.
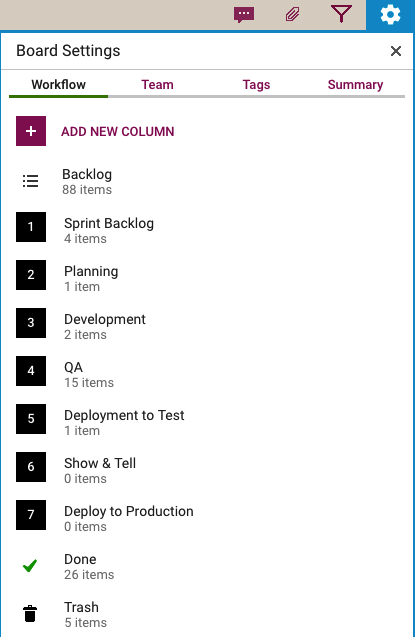
First, a look at our Workflow
Every software development team will want to set up its own workflow, of course, reflecting its internal dynamics and available resources. Here’s the Scrum Board workflow we use in our team:
Scrum Workflow
Our Scrum Boards are organized with these columns:
The Backlog contains all the ideas, large and small, that we have on our product road map: in Scrum terminology, it’s our Product Backlog.
The Sprint Backlog is the set of cards that we pulled from the Backlog at the start of this Sprint: right now, only 4 items are left as we are close to the end of our 2-week Sprint Cycle.
Within each Sprint, cards are picked up developers and first moved into the Planning column, where detailed analysis of the work to be done is completed.
Depending upon the complexity of a particular work item, a developer may request a design review before moving the card further into the Development column.
Developers do their own unit testing as part of the Development phase, but then the work item moves further down to the the QA column which frequently includes formal code review. (More on that below…)
After a bug has been fixed, had its code reviewed and passed unit testing, it gets Deployed to the Testenvironment.
We usually wait until the 2-week Sprint is over before asking the entire team to present the entire Sprint’s output to the Product Owner for the Show & Tell; this avoids distracting the team midway through the Sprint.
Once the output of a Sprint has passed the Show & Tell, it can then be Deployed toProduction.
The Done column shows all the work that got done in this Sprint. That’s where all cards are supposed to go, but sometimes a work item is abandoned and moved to the Trash.
(Side note: we sometimes use WIP Limits to make sure that people are not over-committed to work, but this is not a consistent practice within our team.)
Logging the bug
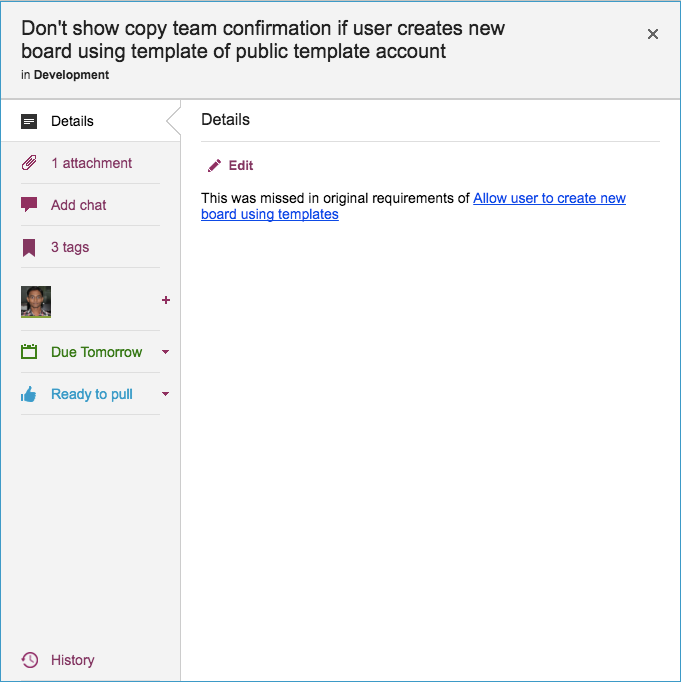
Now, let’s take a look at an example of an actual bug card that was worked on by our team:
Example of a bug tracked as a Kerika card
(This particular bug doesn’t have a lot in the details, because it is related to another task that is currently underway, and Kerika makes it easy to link cards, canvases or boards.)
Some bugs go into the Product Backlog, if they are not considered especially urgent, but others go straight into the Sprint Backlog if they represent serious production problems that might affect user’s access or the reliability of their data.
Adding bugs to the Product Backlog lets us process bugs along with other development, e.g. of new features, in the same way: everything can be prioritized by the Product Owner and handled through a consistent workflow.
Documenting the bug
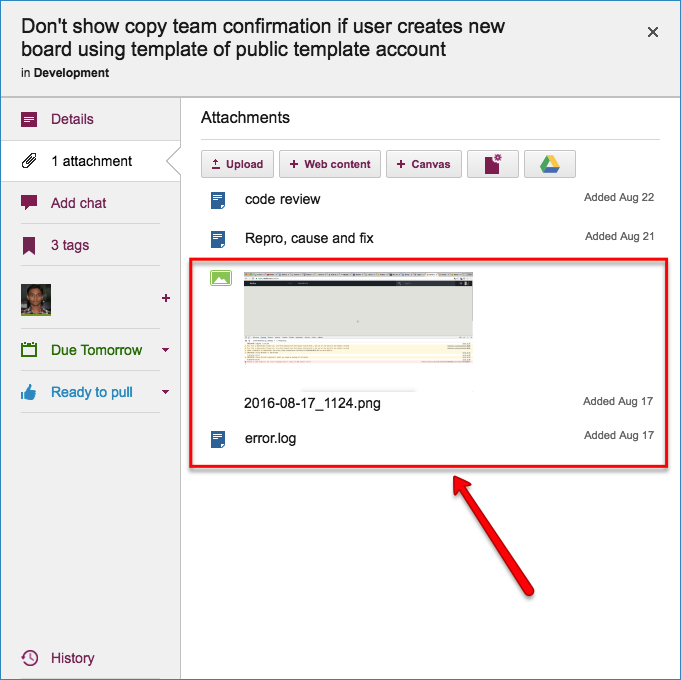
Our bug reports typically come with two attachments; at least one of these should always be included so that the developer has a clear starting point for her work:
A screenshot showing the user experience (if the bug can be observed directly by the user.)
An excerpt from the error log, if the server reported any errors around the time the bug was observed.
Original bug report documents
Kerika makes it easy to attach any kind of content to any card, canvas or board: for bug fixing, particularly in the analysis phase, this is very useful if the user needs to include URLs, material from Sourceforge or similar sites, links to Github, etc.
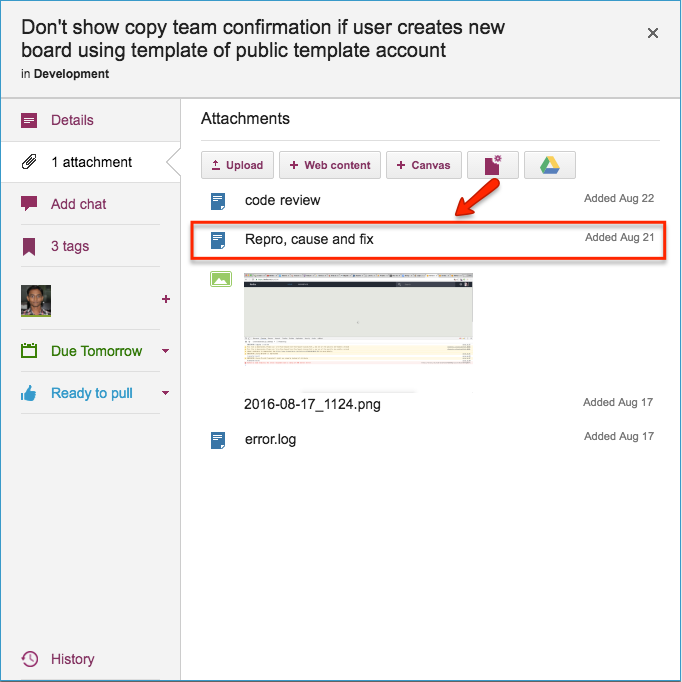
Repro, Cause & Fix
Before any bug is fixed, our developers always add a standard document we call Repro, Cause and Fix as an attachment to the card:
Repro, Cause and Fix
This document is added no matter how trivial the bug.
Why? Because, on average our team goes through about 30-40 cards a week, and has been doing so for years now. If we don’t document our analysis now, we will never recall our logic in the future.
Repro, Cause and Fix
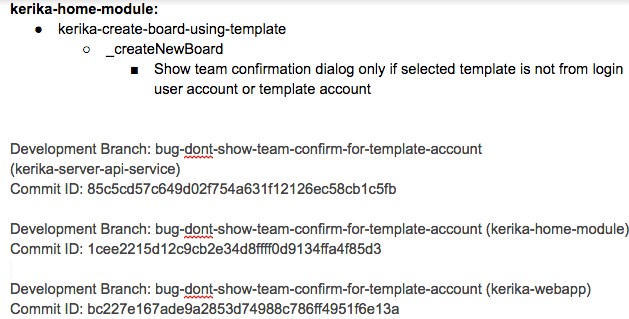
Our team adopts a consistent layout of the Repro, Cause & Fix document, which we adhere to even for trivial bugs:
The Repro Steps are the steps needed to trigger the bug: usually they consist of a specific sequence of actions taken by a user that cause the bug to appear, but they can also consist of a sequence of events in the background, like specific server activity or memory/CPU utilization conditions, or overall network traffic, that trigger the bug.
The Expected Behavior helps clarify the developer’s understanding of the how the software should behave in this situation. It’s not uncommon for a developer who is new to the team to misunderstand how a particular feature is expected to behave, which could lead to more bugs being introduced. Clarifying Expected Behavior in this document provides an easy way for the Product Owner and the Team Lead to confirm that the developer is not going to go down the wrong track.
Introduced Since: our developers try to pinpoint the specific point in the software’s life where the bug was introduced. This helps the developers reflect upon how errors are created in the first place: the blind spots lie in their analytical patterns that need to be strengthened.
(In this particular example, the developer has been able to point back to some of her own work on an earlier feature implementation that caused this bug to appear.)
Root Cause is not the same as the Repro Steps. While a specific sequence of actions or events may reliably display the effects of a particular bug, they only provide the starting point for the analysis; the Root Cause itself is discovered only when the developer examines the code in detail and determines exactly what is breaking.
Affected Feature: all of our code goes through code review, which we view as one of the most effective QA processes we could adopt, but it can be very challenging when you are processing 30 cards each week, each affecting a different part of the software.
Identifying the Affected Feature helps with the code review process, since the reviewer can consider the bug fix in the larger context of the feature that’s being modified. Without this, it is doubtful that we could review so many changes each week.
Affected User: in most cases, this is “everyone” we offer the same Kerika to all our users, whether they are on free trials or have paid for professional subscriptions.
Identifying Affected Users is useful, nonetheless, when dealing with bugs that are browser-specific, or service-specific: for example, determining that a particular bug affects only Kerika+Google users, or only Internet Explorer users.
The Fix: OK, this might seem obvious, but this section really refers to identifying the specific modules in the software that will be changed as a result of the bug fix being applied.
Like many others, we use Git for managing our source code — along with Maven for builds — since our server environment is all Java-based.
The Fix
The Fix section usually includes references to Git checkins: this helps with future bug fixes, by making it easy to traceback sources of new bugs — part of the Introduced Since section described above.
We use separate Git branches for each feature that we develop so that we can decide precisely what gets released to production, and what is held back for future work.
This helps with the Show & Tell phase of our workflow, when the developers demonstrate the output of the Sprint to the Product Owner, who has the option to accept or reject specific features (i.e. cards on the Scrum Board).
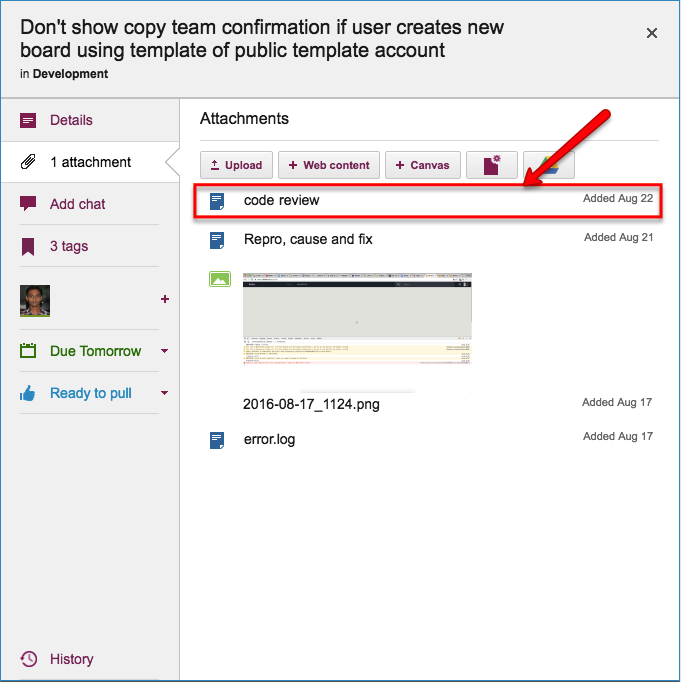
Code Review
All of our code goes through code review, no matter how trivial the change:
Code review
We really believe that code reviews are one of the most effective QA practices we could adopt: having a second pair of eyes look over code can very considerably reduce the chances of new bugs being introduced.
So…
Kerika is great for distributed software teams: our own team is spread out between Seattle and India (roughly 10,000 miles apart!), and all of our work is done using Kerika for task management, content management and team collaboration.
Of course, an added benefit of “eating our own dogfood” is that we are highly motivated to make sure Kerika is the best tool there is for distributed teams 🙂
It’s not that we have sensitive stuff on the blog: quite the contrary. It’s just that we have implemented HTTP Strict Transport Security (HSTS) across the entire kerika.com domain.
It allows web servers to declare that web browsers should only interact with it using secure HTTPS connections, and never via the insecure HTTP protocol.
Since our blog is on a sub-domain of kerika (blog.kerika.com, to be precise), we needed to implement SSL and HTTPS for the blog as well.
If you use Ghostery (which is a pretty cool browser plug-in, by the way), it’s easy to see which “trackers” are being used by a website.
The only tracker that Kerika uses is Google Analytics:
Trackers on kerika.com
Google Analytics is a free service from Google that we use to get a general understanding of who visits Kerika.com, from where, and using which kinds of browsers.
For example, Google Analytics tells us that an amazing 98.27% of all visitors to Kerika.com use the Chrome browser: this is way above the general market share for Chrome, which is about 29.15%!
And that’s the only tracker you will find on Kerika.
Here, by way of contrast, are what news sites like the New York Times and CNN use in terms of trackers:
Trackers on nytimes.com: 11 in totalTrackers on cnn.com: 18 in total
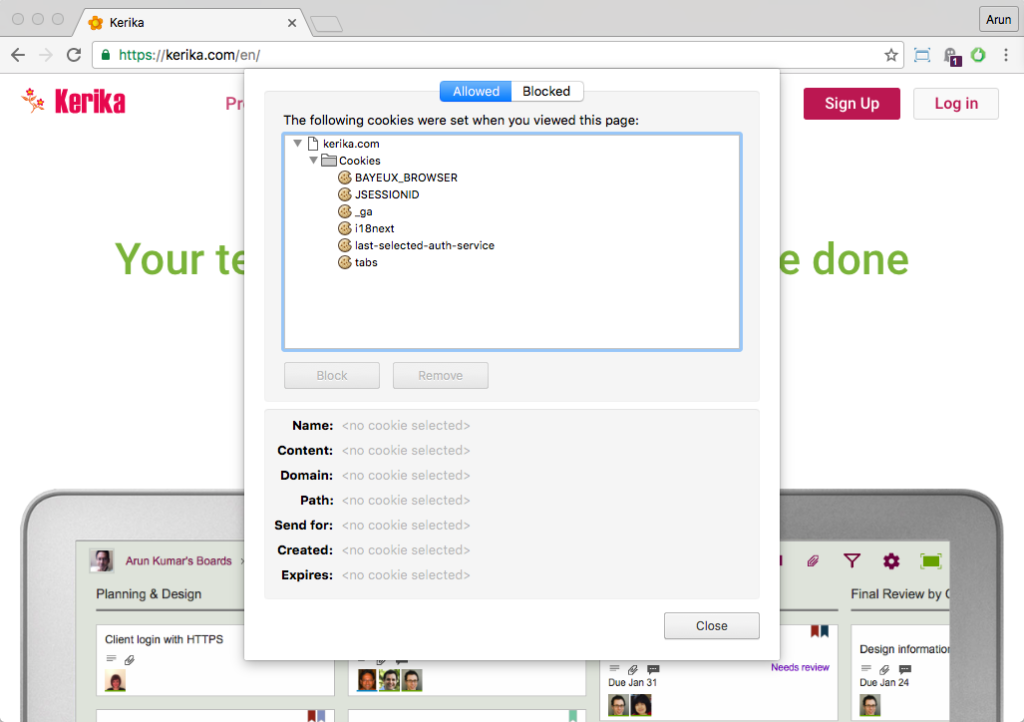
Ever wonder how many cookies Kerika sets when you are logged in, and why?
Here’s the answer:
Kerika’s cookies
The first cookie, called “BAYEUX_BROWSER”, relates to our use of the CometD communications protocol for ensuring that you always get real-time updates whenever you are looking at any Kerika board, no matter which browser you are using.
CometD leverages WebSocket when it can (because it’s the most efficient web messaging protocol), and makes use of an Ajax push technology pattern known as Comet when using HTTP. Most modern browsers support WebSocket, but we still have some older versions of Internet Explorer out there that don’t support WebSocket. This cookie helps us track whether your browser supports WebSocket or not.
The next couple of cookies are used simply to keep track of your Kerika session.
The fourth cookie, “i18next”, is really not used much right now, but we hope to make greater use of it in the future.
Right now Kerika is available only in English, but the code was always written to make it easy for us to create versions in other languages, e.g. Spanish, Chinese, etc. This process is called “internationalization”, and is usually abbreviated as “i18n” by us nerds.
The last two cookies, “last-selected-auth-service” and “tabs”, are used to remember what you were last doing when you were logged into Kerika on that computer: when you log back in, after having logged out, these two cookies help us restore your view of Kerika to exactly where you left off.
As it says on our website, we are committed to transparency, so now you know everything about our cookies.
We offer three ways for you to sign up as a Kerika user:
Using a Google ID, e.g. a Gmail address if you have one.
Using a Box ID, if you are a Box user.
Signing up directly.
Using a Google ID means you are getting Kerika+Google: the version of Kerika that offers amazingly smooth integration with your Google Drive and Google Docs.
Using a Box ID means that you are getting Kerika+Box: the version that offers amazingly smooth integration with the Box platform.
And signing up directly means that you can use any email address you like, and leave it to Kerika to store your files for you.
Originally, we had just Kerika+Google, and then we built Kerika+Box to address the market for enterprises that preferred using Box to Google.
And, finally, we built the direct login method for people who didn’t care about how their Kerika files were stored, and were happy to just leave that whole job for us to take care of.
We are now trying to streamline that process even further.
If you already have a Gmail address, it is very likely that you are already comfortable with using Google’s services, which means you should really be getting a Kerika+Google account so that you can benefit from all the great, smooth integration we have already done.
In the same vein, if the majority of people from your company have already signed up for a particular service, e.g. Kerika+Box or Kerika+Google, then it makes sense for you to sign up in the same way so that you can share boards with your coworkers.
This process is now more automated, and, we hope, simpler: when you sign up, we look at the email address you are using to set up your Kerika account and try to set you up with the version of Kerika that will make most sense:
If you are signing up with a Gmail address, we are going to set you up with Kerika+Google.
If most people from your company have already signed up for Kerika+Box, or Kerika+Google, we will set you up the same way as well.
This should make for less confusion about which flavor of Kerika is going to be tastiest for you…
Sorry for not having posted in a while; we have been swamped with a new UI design that has consumed all of our time.
The new UI, by the way, is all about making Kerika more accessible, particularly to people who are new to visual collaboration.
Our user feedback had revealed a couple of uncomfortable truths that we needed to address:
Very few users were aware of all the functionality that already exists in Kerika. Which means that we didn’t need to focus so much on building new functions as we did on making sure people understand what Kerika can already do.
Our new users aren’t just new to Kerika; in most cases, they are new to visual collaboration altogether. Even though there has been a proliferation in recent months of all sorts of companies trying to recast old, tired products as exciting new visual collaboration (hello, Smartsheet!), our new users aren’t converting away from our competitors as much as converting away from paper, email, and SharePoint.
This, then, is the goal of our new UI: to make it easier for people to adapt from paper and email to visual collaboration, and to make it easier for all users to exploit all the great functionality that we have already built.
We will have more on this in the coming months, as we get closer to releasing our new user interface, but in the meantime we have queued up a bunch of blog posts to make sure you know about all the other great stuff we have been working.
Yeah, our biggest problem is we don’t tell people what we have already done…
This website uses cookies to improve your experience. We'll assume you're OK with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.