Between 9AM and 11AM Pacific Standard Time, Google’s authentication service threw up about about 60 errors, which gave many of our users a rough ride.
The problem was that Google’s authentication servers were timing out repeatedly, showing errors like this:
Request URL: https://kerika.com/authcallback/google?code=XXXXXXXX
Request Method: GET
Status Code: 504 Gateway Timeout
There isn’t anything we can do in this situation to help our Kerika+Google users, unfortunately, since Google’s authentication service needs to be up and running in order to log in to Kerika.
The silver lining in this cloud, for now, is that this is a relatively rare occurrence.
Our newest update to Kerika serves up a rather long list of changes; the two big areas for improvement were:
We have updated our integration with Google Apps Marketplace to use OAuth 2.0, since Google is retiring its OAuth 1.0 implementation.
We have made a bunch of improvements for using Kerika on iPads, with the Safari or Chrome browsers. (We still need to work on Android tablets, which, unfortunately, present too much variety…)
The OAuth 2.0 upgrade and iPad improvements are described in previous posts; here we want to highlight some of the other changes and improvements we made with this new version:
We have changed the way colors show on cards, on Task Boards and Scrum Boards to make them more usable:
In addition to being less distracting, this new design will enable us to expand the palette of colors we can offer: the old design restricted us to only the lighter pastel colors.
New styling for colored cards
We have redesigned our “Max Canvas” view so that it provides the most useful display, when you need the most space available to view a large board. In particular, you can now access Search even when you are in the Max Canvas view.We have improved security, by implementing secure cookies.
We added some subtle animation effects to improve usability. (So subtle, in fact, that you might not even notice them if you are an existing Kerika user, which is just what we want.)
In terms of infrastructure and other under-the-hood improvements, we have expanded our use of JUnit automated tests and done a bunch of bugs fixes, as usual.
There’s a lot of improvements being done on Kerika, and at a very fast rate. Make sure you subscribe to our blog to keep up!
OK, so our website has long stressed the word “unlimited”, and maybe that’s not such a great idea…
Most people have boards with a few dozen cards.
Some folks have boards with a couple of hundred cards.
Very few people have boards with up to 1,000 cards.
It turned out that one of our users had a board with nearly 4,200 cards, of which over 4,000 were in the Trash.
And that’s not good! A board with several thousand cards on it is going to take a long time to load, because each card has many different attributes to it: details, chat, assignments, status, history, etc.
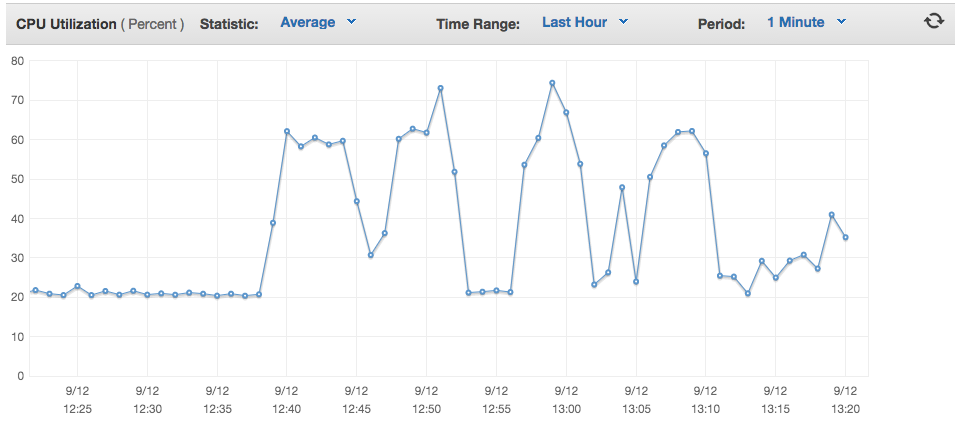
And when someone with a very large board uses Kerika, this can cause very unexpected loads on the servers, particularly in terms of network I/O and CPU utilization.
This is what it looks like when someone suddenly opens a board with thousands of cards on it:
Most of the time, boards get very big because they are very old: stuff piles up in the Done column, or, as in this case, in the Trash column.
Having very large boards can impact performance: unlike, say, email which you may be accustomed to leaving piled up in your Inbox for years on end, Kerika’s cards are “live object”: even when a card is in the Done or Trash columns, it is constantly listening for updates from the server, because it could be moved out of Done or Trash at any time by someone on the team, or have some of it’s attributes changed.
For example, even though a card is “Done” or “Trashed”, it could have its details updated, or new chat added to it.
This is different from email messages, which are essentially “dead objects”: once you get an email and read it, it doesn’t update after that, so it can sit for years in your Inbox without trying to get fresh updates from the mail server.
So, when you have 4,200 cards on a single board, you have that many live objects trying to get updates from the server at the same time, and that’s not good for your browser or our server!
(Imagine your laptop trying to read and display 4,200 emails at the same time, and you will get an idea of the problem…)
Having very large boards is not a good idea from a workflow or process management perspective, and so perhaps Kerika needs to do something about it: we need to think about how we can help our users improve their workflow, while also avoiding these CPU spikes.
A couple of ideas that we are considering:
Start warning users when their boards are getting too big.
If boards hit some threshold values (which we have yet to figure out, maybe it’s 1,000 cards?) force the user to reconfigure their board so they don’t affect the quality of the service for everyone.
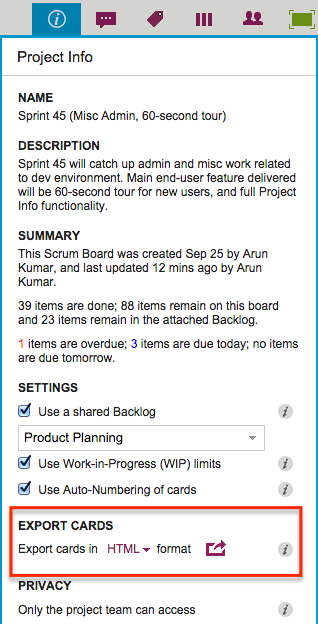
To access this feature, simply click on the Project Info button that’s shown at the top-right of each Kerika Board, and you will see the Project Info display (that we have talked about in an earlier blog post):
Export
CSV format is useful if you want to want to take data from Kerika and put it into Excel or some other analysis tool;
HTML format is useful if you want to print material from Kerika, or insert it into Word, PowerPoint or similar tools.
With both CSV and HTML exports, hidden cards are not exported: this means that if you are currently choosing to hide some columns (by using the Workflow button), or hide some cards (by using the Tags filters), then the cards that you are not viewing right now will not be part of the export.
When you export a board in CSV format, you get the following data, for each visible card:
Example of CSV export
Column Name: e.g. Backlog, In Progress, Done, etc.
Card Name: e.g. “Create PR news release”.
Card Description: e.g. “We need to create a PR news release once our latest version is ready…” (Rich text will be converted to plain text, since CSV files can only deal with plain text.)
Status: e.g. Needs Review, Needs Rework, etc. (If the card doesn’t have a special status, “Normal” will be shown.)
Due Date: the date the card is due, if a date has been set. (If the card doesn’t have a Due Date, “Not Scheduled” will appear.)
Assigned To: a list of names of the people the card is currently assigned to. (If the card isn’t assigned to anyone, “Not Assigned” will appear.)
Exporting could take a while: the exported data are put into a file in your Google Drive or Box account — depending upon whether you are using Kerika+Google or Kerika+Box — and when the process completes, you get an email with a link to the file containing your data.
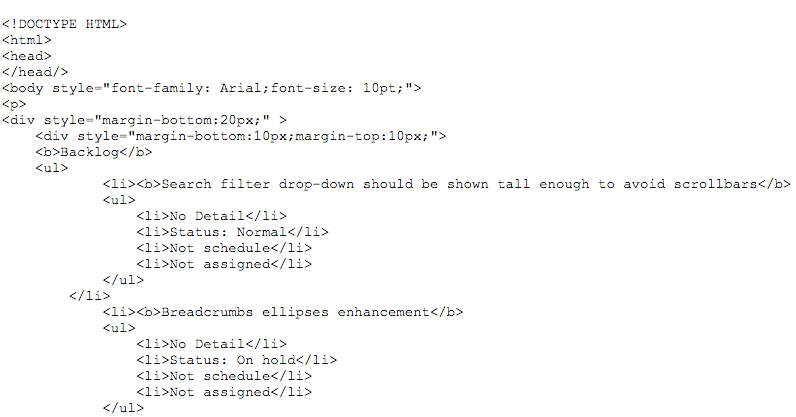
It’s a similar experience if you do a HTML export; however the format of the data is different, giving you an indented set of attributes for each card, like this example from a Kerika+Box project:
Example of HTML export from Kerika+Box
One caveat about exporting HTML: if you open the results in Google Docs, Google shows a preview of the output, and that doesn’t look good: instead of rendering the HTML, Google actually exposes it.
Here’s an example from a Kerika+Google project:
Example of HTML export from Kerika+Google
The export feature can be used for many different purposes, of course: the most common scenario we envision is people wanting to include material from Kerika in their analysis and presentations.
And, of course, one use would be for government agencies that have to respond to Freedom of Information Act (FOIA) requests, or other Sunshine laws.
Arun Kumar, Kerika’s CEO, will present at the Washington State Office of Financial Management (OFM) Fall Forum, at 1:30PM on September 17, 2014 at the Thurston County Fairgrounds in Olympia, Washington.
The topic will be experimentation with Visual Management in government and administrative processes.
Arun Kumar, Kerika’s CEO, will present a special Breakout Session on One team, many places: creating collaboration networks for distributed workgroups
The vision of Lean Government is about collaborating across offices, across agencies, and even across sectors. In an era of flat or even declining budgets, it’s become essential to get Lean across the state, not just across the room.
The old technologies never really supported distributed Lean and Agile, but that’s all changed now: a new generation of browser-based work management tools makes it fast and easy to build Lean and Agile teams that connect professionals across agencies, and across sectors so that expertise from the private sector, academia, and nonprofits can be leveraged to deliver great results in Washington.
This breakout session will feature a look at some great cross-agency projects and cross-sector projects: initiatives that have succeeded in delivering in a way that was unimaginable only a couple of years ago.
The session will be presented at 12:15PM in Room 318 on October 21, and again at 10AM in Room 318 on October 22.
If you are working in state, county or local city government and are interested in Lean and Agile, be sure to join us: the cost for attending is just one can of food, which will be donated to a food bank 🙂
We were at Boxworks14 last week, and had a great time!
We met a bunch of interesting folks, including Heidi Williams, Senior Director of Platform Engineering, who — along with Peter Rexer and others from her team — gave some really insightful deep-dives into Box’s technology stack.
(Among other things we learned that we could improve the Kerika user experience by changing the way we do OAuth 2.0 with Box.)
Keynote speeches were amazing: the hyper-kinetic Aaron Levie made for a rousing start, but the real star was Jared Leto who not only brought his Oscar onstage, but in a jaw-dropping move handed it over the audience for people to take selfies with while he blithely continued with his “Fireside Chat”.
Jared’s move even upstaged Aaron, which is pretty hard to do (as you will know, if you have ever encountered Aaron in the flesh…)
Other great speakers included Jim Collins, author of Built to Last, Vinod Khosla of Khosla Ventures (and, originally, Kleiner Perkins and Sun Microsystems), and Andrew McAfee from MIT.
We are sometimes asked (usually by our more techie users) whether Kerika has a published API.
The short answer is “No”; the longer answer is “Not yet.”
We do have a server API, of course, that the Kerika front-end client application itself uses, but it is a very proprietary and non-standard API at present.
This is largely because of an early decision we made to use CometD for our real-time client-server communications.
CometD is a form of a long-poll architecture, but our implementation, unfortunately, is not very standard, in part because we built an “API generator” a long time ago that allows us to create new APIs fairly quickly using metadata descriptions of the desired features.
This was helpful when we were first getting started, but, quite honestly, it isn’t an approach that makes a lot of sense any more and we have migrated away from using that API generator.
But, because of our history/legacy code, we currently have a mix of auto-generated APIs and newer API, and this isn’t really something that we want to publish and support for external third-party development.
We plan to redo our API this year to make it more standard and easier for third-party developers to use, at which point we will publish it and start encouraging more platform development around Kerika.
We often get asked if Kerika has an integration with Git. The short answer is “No”, but the longer answer is more nuanced…
We use Git ourselves for managing our own source code and other software assets.
Git was designed from the git go (ha!) to be used by distributed teams, having originated with the Linux kernel team, perhaps the most important distributed team in the whole world, so it made perfect sense for us to use it: it works across operating systems, and a number of simple GUIs are now available for managing your various source-code branches.
We simply embed the git references within cards on our project boards: sometimes in the chat conversation attached to a card, but more often within the card’s details.
Here’s an actual example of a bug that we fixed recently:
Example of Git integration
We use multiple Git branches at the same time, because we put every individual feature into a separate branch.
That’s not a fixed rule within Git itself; it’s just our own team’s practice, since it makes it easier for us to stick with a 2-week Sprint cycle: at the end of every 2 weeks we can see which features are complete, and pull these git branches together to build a new release.
So while Kerika doesn’t have a direct integration with Git, it’s pretty easy to use Kerika alongside Git, or other source management systems.
This website uses cookies to improve your experience. We'll assume you're OK with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.