We currently have a function to let you Cut/Copy and then Paste a project from one account to another, but it’s starting to look like this is a bad idea because it is very difficult to implement cleanly.
The underlying problem is that a project is more than a collection of cards: it is also part of a network of people relationships, connections to other projects, etc., and these can’t all be moved cleanly from one account to another.
For example, consider a series of projects that are organized as Scrum Boards, linked to a shared Backlog within one account. If we copy and paste one of these projects to another account, what exactly should happen to that Backlog? It’s not an easy matter to simply copy the entire Backlog over as well, to the new account — that may not be the most sensible outcome in all, or even most, circumstances.
Consider an even more basic problem: a project has a bunch of folks working on it today. If you copy and paste the project to another account, what should happen to this team? These folks may not have previously been part of the new account’s team: they would have to get invited to join projects in that account, and very likely the new account’s owner would have to upgrade her account to support the larger team size.
There a bunch of conundrums like this to work through, and it’s not clear that this is even worth the considerable effort it would take to create a bullet-proof solution – how often, after all, do people need to move a project from one account to another?
If the answer is “not very often”, then it’s probably better for us to remove this functionality, rather than leave users with a less-than-great experience…
System that Captures and Tracks Energy Data for Estimating Energy Consumption, Facilitating its Reduction and Offsetting its Associated Emissions in an Automated and Recurring Fashion
Here’s a quick primer on how to delete projects you are no longer working on, and how to retrieve them later from your Trash (think “Recycle Bin” if you are a PC user) if you change your mind.
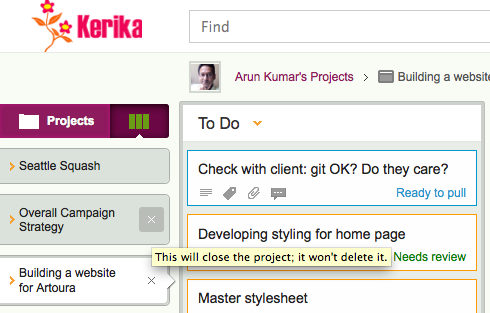
The first point to note is that closing a project is not the same as deleting it: when you are looking at your Boards view, you can have several projects open, each in its own tab. If you hover over any of the project tabs, you will see an “x”: clicking this will close the project.
Closing a project tab
This is a lot like closing a browser tab: it doesn’t kill the website that you were viewing; it just means you are no longer viewing it yourself. In the same way, closing a project tab doesn’t delete the project.
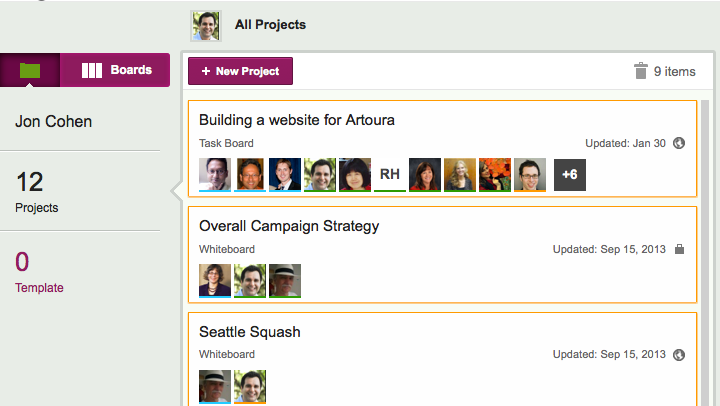
If you actually want to delete a project, click on the “Projects” button, in the top-left corner of the Kerika app (as shown above), and you will see a list of all your projects:
Viewing all your projects
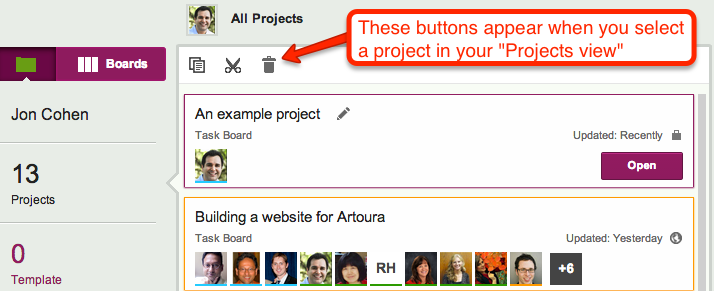
Here, you can select an individual project, and then Cut, Copy, or Delete it:
Project operations
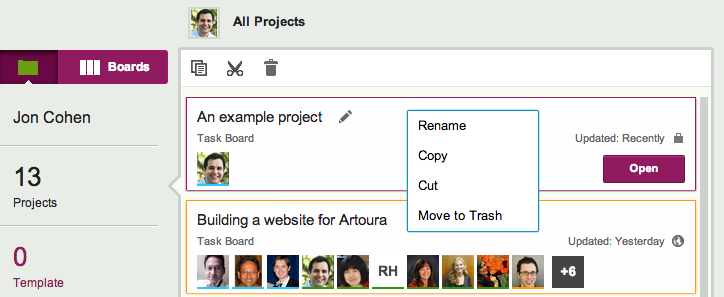
These buttons also appear when you use your right-mouse button, while working on a desktop or laptop:
Right-click menu
If you click on the Trash button (or select “Move to Trash” from the right-click menu), your project will get deleted.
Deleted projects go into a Trash, which is like a Recycle Bin: you can retrieve it later if you change your mind or make a mistake.
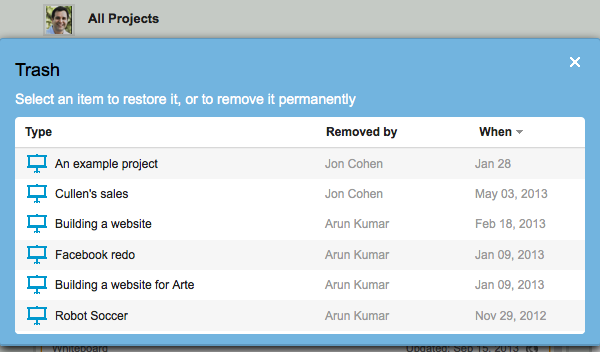
The Projects Trash appears just above your list of projects:
Projects Trash, in the Projects View
Whenever a project is moved to the Trash, the Project Trash button glows orange, briefly, to alert you. Click on the button and you will see a list of all the projects that are in your Projects Trash:
Viewing the Projects Trash
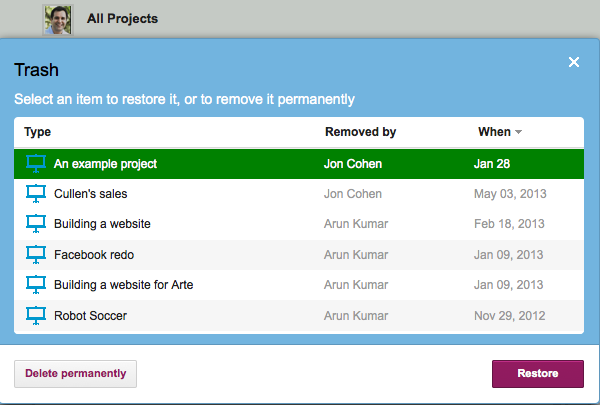
You can now select an individual project, and choose to either restore it, or delete it permanently:
Restoring a project
So, that’s it: a simple way to delete projects, and retrieve them later if you made a mistake.
Every card, every canvas, every board in Kerika has a unique URL.
This makes it really easy to link items together, by using the URL in a card’s chat or description. And, with our latest version, Kerika makes this even easier by showing the title of the other card. Check out this quick tutorial video:
We have added a couple of new features related to dates:
Every card in the Done column, of a Task Board or Scrum Board, will show the date on which the card was marked as done: this makes it easy to see, at a glance, when work was completed on a project.
Cards that have dates assigned to them can get sorted by date.
If a column contains any cards with dates assigned to them, a “Sort by Date” button appears at the top of the column:
Sort by Date button
Clicking on this button will sort the cards that have dates:
Only cards with dates are affected: if a column contains some cards that don’t have dates, these are not affected.
You can sort in ascending or descending order.
This is a useful feature for date-driven projects, but if you are working in a pure Kanban or Scrum team, you might want to stick with (manually) sorting dates by priority, which the highest priority items at the top of the column.
We are replacing our integration with Google Docs with a “friends of friends” model.
The Background:
For the past 2 years, Kerika has offered an “auto-completion” feature that let you type just a few characters of someone’s name, and then have a list of matching names and emails appear from your Google Docs. It looked like this:
Auto-completion of invitations
This was actually a very helpful feature, but it was also scaring off too many potential users.
The Problem:
When you sign up as a new Kerika user, Google asks whether it is OK for Kerika to “manage your Google Contacts”. This was a ridiculous way to describe our actual integration with Google Contacts, but there wasn’t anything we could do about this authorization screen.
We lost a lot of potential users thanks to this: people who had been burned in the past by unscrupulous app developers who would spam everyone in their address book. So, we concluded that this cool feature was really a liability.
The Solution:
We are abandoning integration with Google Contacts with our latest software update. Existing users are not affected, since they have already authorized Kerika to access their Google Contacts (and are, presumably, comfortable with that decision), but new users will no longer be asked whether it is OK for Kerika to “manage their Google Contacts”.
Instead, we are introducing our own auto-completion of names and email addresses based upon a friends of friends model: if you type in part of a user’s email, Kerika will help you match this against the names of that are part of your extended collaboration network:
People you already work with on projects.
People who work with the people who work with you.
We hope this proves to be a more comfortable fit for our users; do let us know what you think!
A month ago we wrote about how Kerika makes it really easy to spot bottlenecks in a development process – far easier, in our opinion – than relying upon burndown carts.
That blog post noted that the Kerika team itself had been struggling with code reviews as our major bottleneck. Well, we are finally starting to catch up: over the past two days we focused heavily on code reviews and just last night nearly 80 cards got moved to Done!
(Updated April 6, 2014 to reflect changes by Google)
If you are going to use Kerika for business, and don’t have a premium Google Apps account, make sure you create a new Google ID that maps to your existing (business) email ID.
For example, if you are someone@somecompany.com, you can create a new Google ID that is “someone@somecompany.com”: it works just like any other Google ID, and it doesn’t require you to switch to Gmail or anything like that.
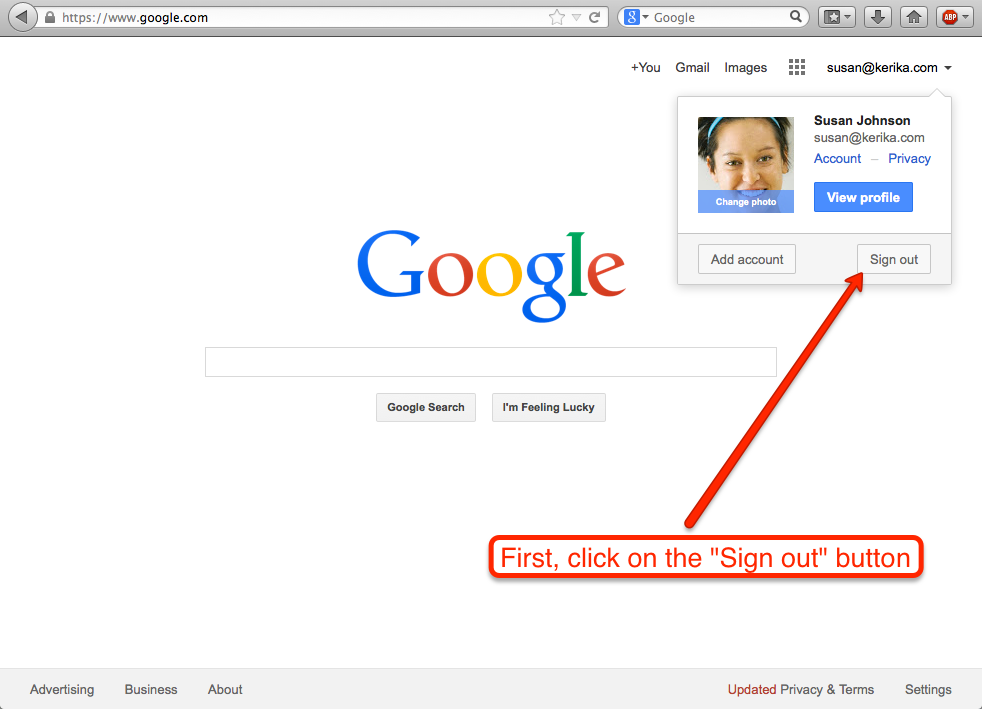
First, sign out of your old Google account:
First, click on the Sign out button
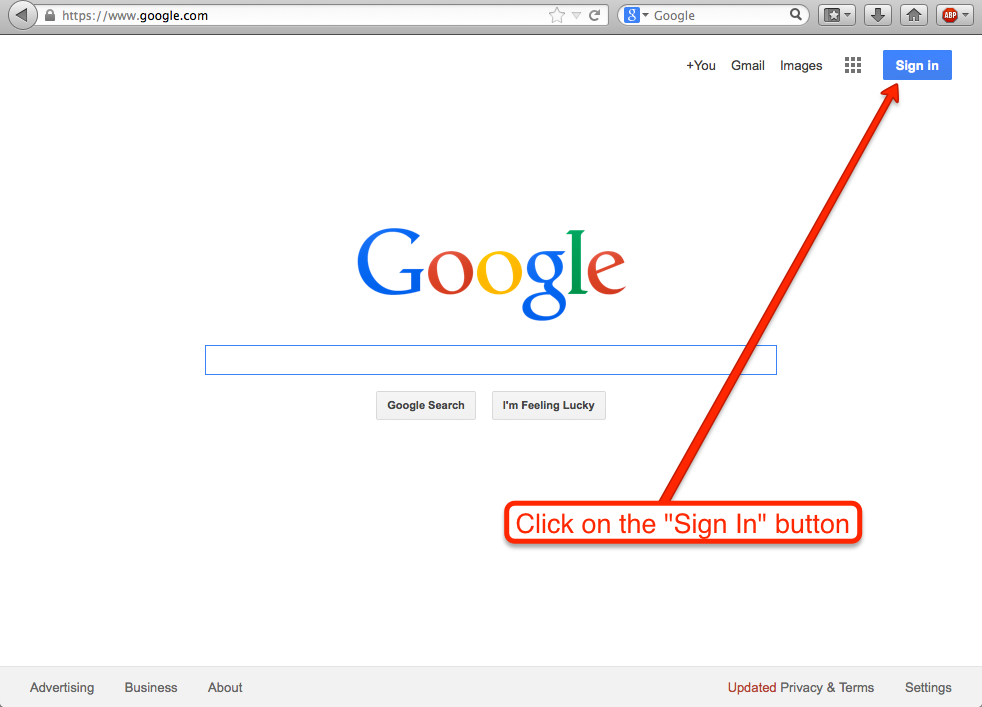
Then, click on the Sign In button at the top-right:
Click on the Sign In button
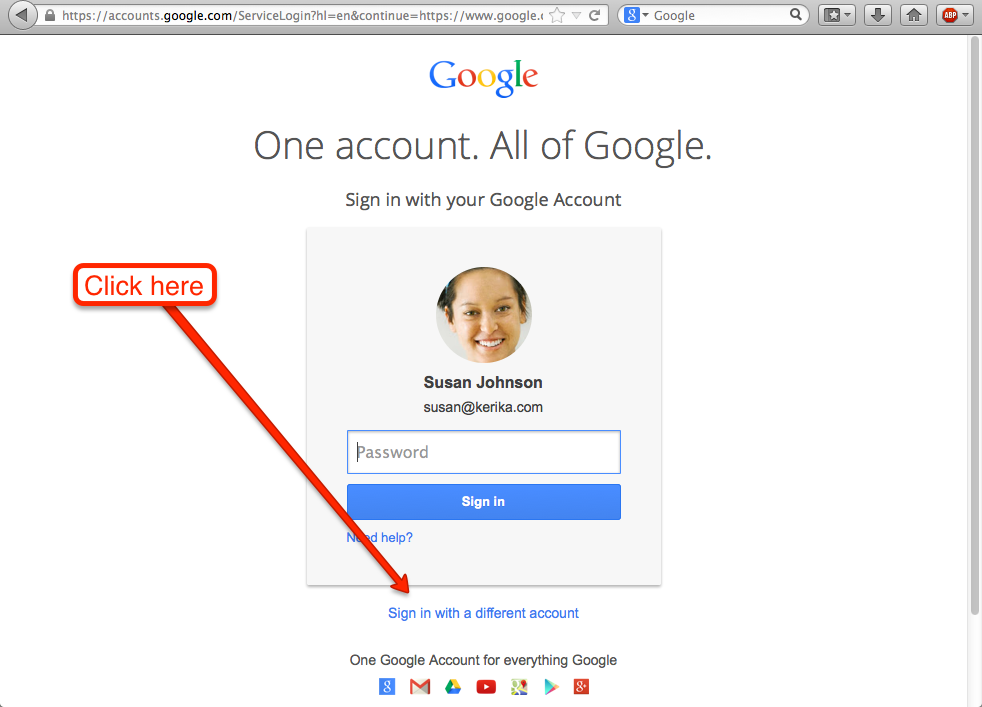
Before you create a new Google ID, you need to make sure you have completely signed out of your old Google ID. To do that, click on Sign in with a different account:
Click on Sign in with a different account
This step is scary-looking (intentionally?), but you need to Remove your account first. This doesn’t mean that you are actually closing or deleting your old Google account, it just means you are finally removing Google’s cookie from your browser.
Click here to make sure you are completely logged out
Clicking on Remove brings up this screen:
Click on the X button
Now you are finally logged out of Google!
Now you are finally logged out of Google
Now, you are ready to set up a new Google account. Click on the Create an account link:
Click here to create a new account
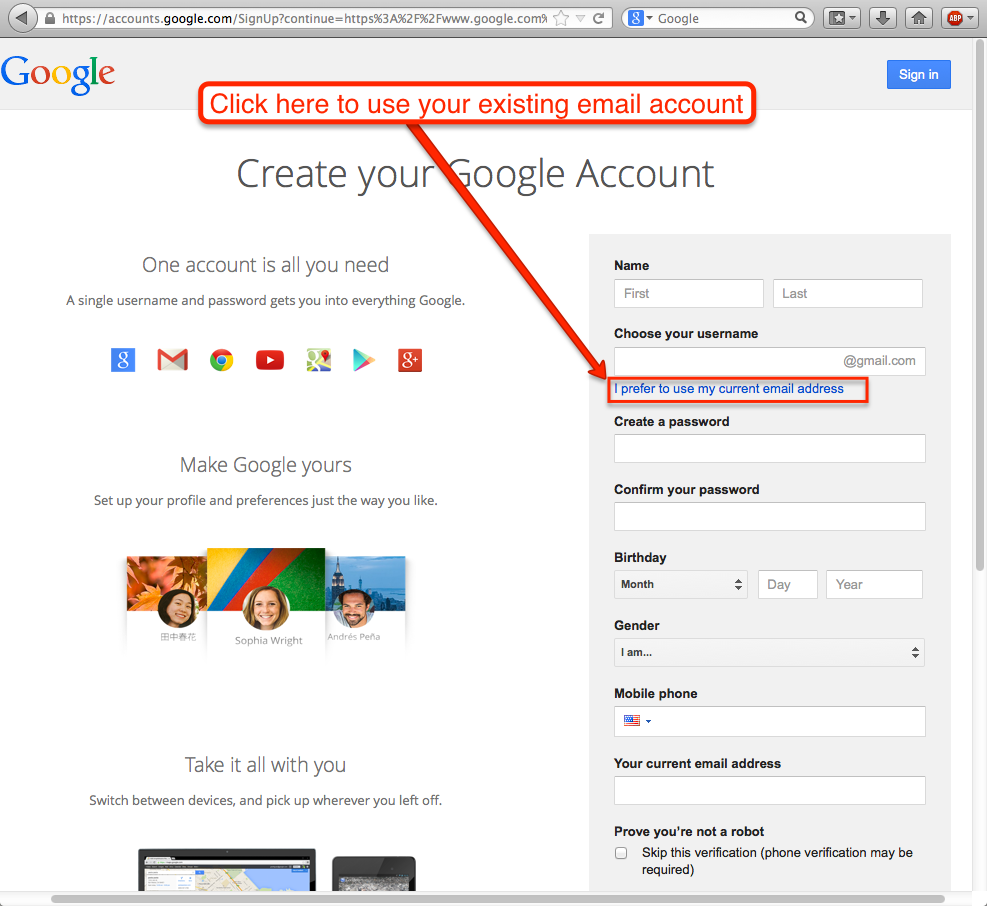
Click on I prefer to use my current email address
Click here to use your existing email account
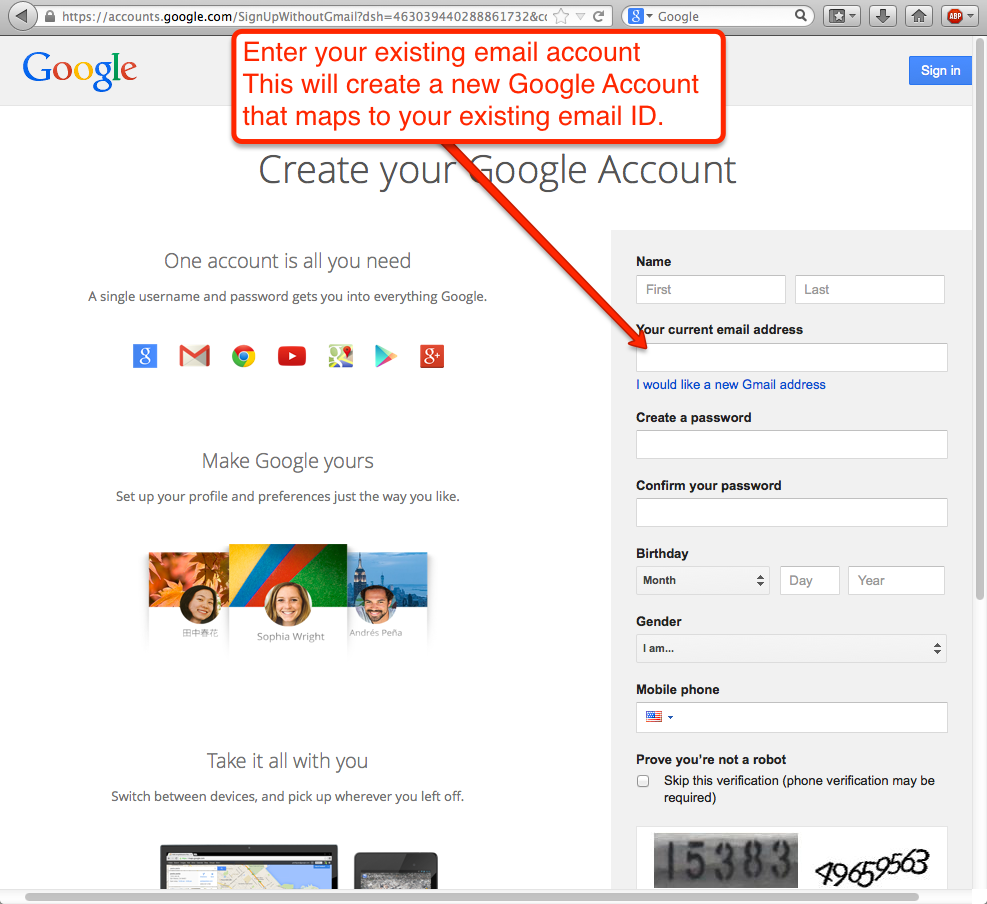
And, you are finally ready to create a new Google ID, that maps to an existing business email. This could be an email ID from anywhere: you can use a Yahoo email or a Hotmail ID, as well as any email ID from your employer.
Final step
Creating a new Google ID in this way doesn’t mean you are switching to Gmail!
We have been experiencing a CPU spike on one of our servers over the past week, thanks to a batch job that clearly needs some optimization.
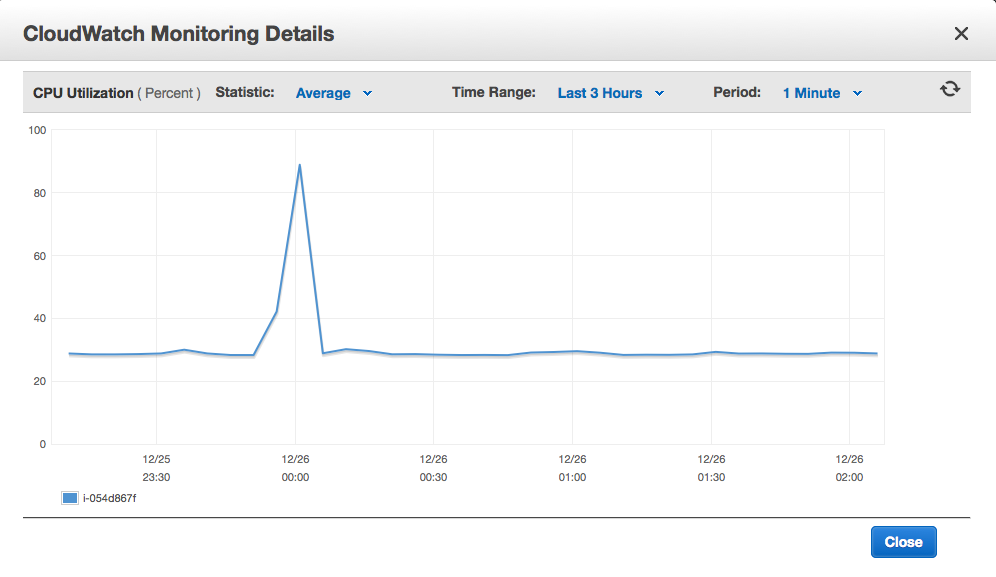
The CPU spike happens at midnight, UTC (basically, Greenwich Mean Time), when the job was running, and it looks like this:
CPU spike
It’s pretty dramatic: our normal CPU utilization is very steady, at less than 30%, and the over a 10-minute period at midnight it shoots up to nearly 90%.
Well, that sucks. We have disabled the batch job and are going to take a closer look at the SQL involved to optimize the code.
Our apologies to users in Australia and New Zealand: this was hitting the middle of their morning use of Kerika and some folks experienced slowdowns as a result.
Talk to old-timers at Microsoft, and they will wax nostalgic about Windows Server 2003, which many of the old hands describe as the best Windows OS ever built. It was launched with over 25,000 known bugs.
Which just goes to show: not all bugs need to be fixed right away.
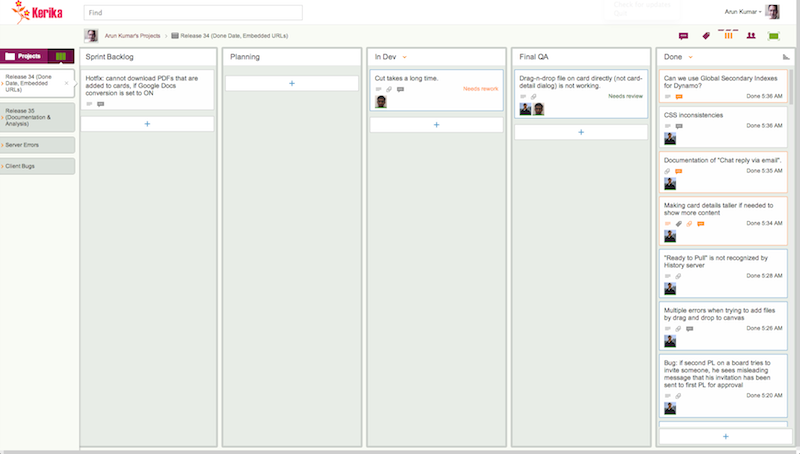
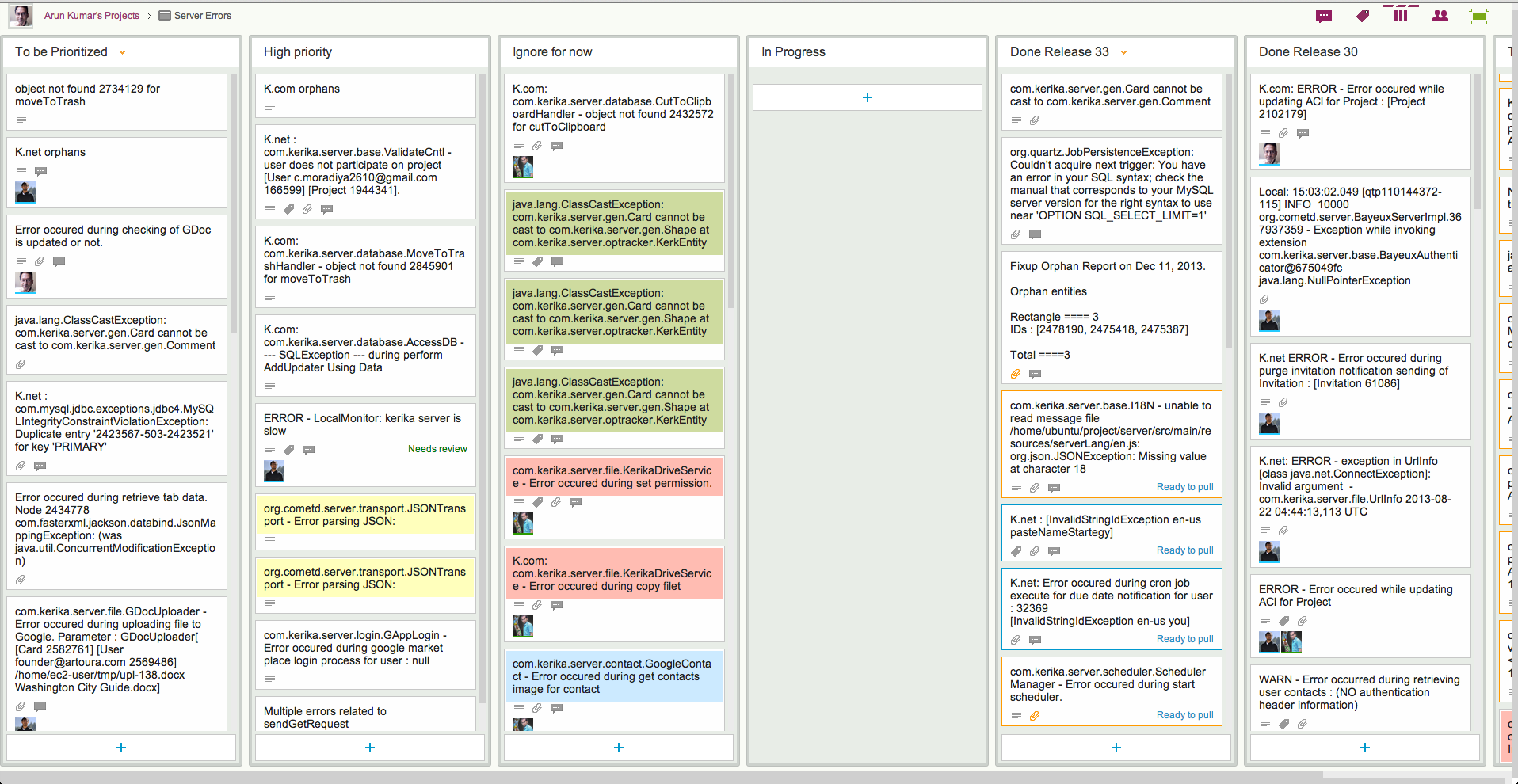
Here at Kerika we have come up with a simple prioritization scheme for bugs; here’s what our board for handling server-related bugs looks like:
How we prioritize errors (click to enlarge)
This particular board only deals with exceptions logged on our servers; these are Java exceptions, so the cards may seem obscure in their titles, but the process by which we handle bugs may nonetheless be of interest to others:
Every new exception goes into a To be Prioritized column as a new card. Typically, the card’s title includes the key element of the bug – in this case, the bit of code that threw the exception – and the card’s details contain the full stack trace.
Sometimes, a single exception may manifest itself with multiple code paths, each with its own stack trace, in which case we gather all these stack traces into a single Google Docs file which is then attached to the card.
With server exceptions, a full stack trace is usually sufficient for debugging purposes, but for UI bugs the card details would contain the steps needed to reproduce the bug (i.e. the “Repro Steps”).
New server exceptions are found essentially randomly, with several exceptions being noted in some days and none in other days.
For this reason, logging the bugs is a separate process from prioritizing them: you wouldn’t want to disturb your developers on a daily basis, by asking them to look at any new exceptions they are found, unless the exceptions point to some obviously serious errors. Most of the time the exceptions are benign, and perhaps annoying, rather than life-threatening, so we ask the developers to examine and prioritize bugs from the To be Prioritized column only as they periodically come up for air after having tackled some bugs.
Each bug is examined and classified as either High Priority or Ignore for Now.
Note that we don’t bother with a Medium Priority, or, worse yet, multiple levels of priorities (e.g. Priority 1, Priority 2, Priority 3…). There really isn’t any point to having more than two buckets in which to place all bugs: it’s either worth fixing soon, or not worth fixing at all.
The rationale for our thinking is simple: if a bug doesn’t result in any significant harm, it can usually be ignored quite safely. We do about 30 cards of new development per week (!), which means we add new features and refactor our existing code at a very rapid rate. In an environment characterized by rapid development, there isn’t any point in chasing after medium- or low-priority bugs because the code could change in ways that make these bugs irrelevant very quickly.
Beyond this simple classification, we also use color coding, sparingly, to highlight related bugs. Color coding is a feature of Kerika, of course, but it is one of those features that needs to be used as little as possible, in order to gain the greatest benefit. A board where every card is color-coded will be a technicolor mess.
In our scheme of color coding, bugs are considered “related” if they are in the same general area of code, which provides an incentive for the developer to fix both bugs at the same time since the biggest cost of fixing a bug is the context switch needed for a developer to dive into some new part of a very large code base. (And we are talking about hundreds of thousands of lines of code that make up Kerika…)
So, that’s the simple methodology we have adopted for tracking, triaging, and fixing bugs.