Talk to old-timers at Microsoft, and they will wax nostalgic about Windows Server 2003, which many of the old hands describe as the best Windows OS ever built. It was launched with over 25,000 known bugs.
Which just goes to show: not all bugs need to be fixed right away.
Here at Kerika we have come up with a simple prioritization scheme for bugs; here’s what our board for handling server-related bugs looks like:
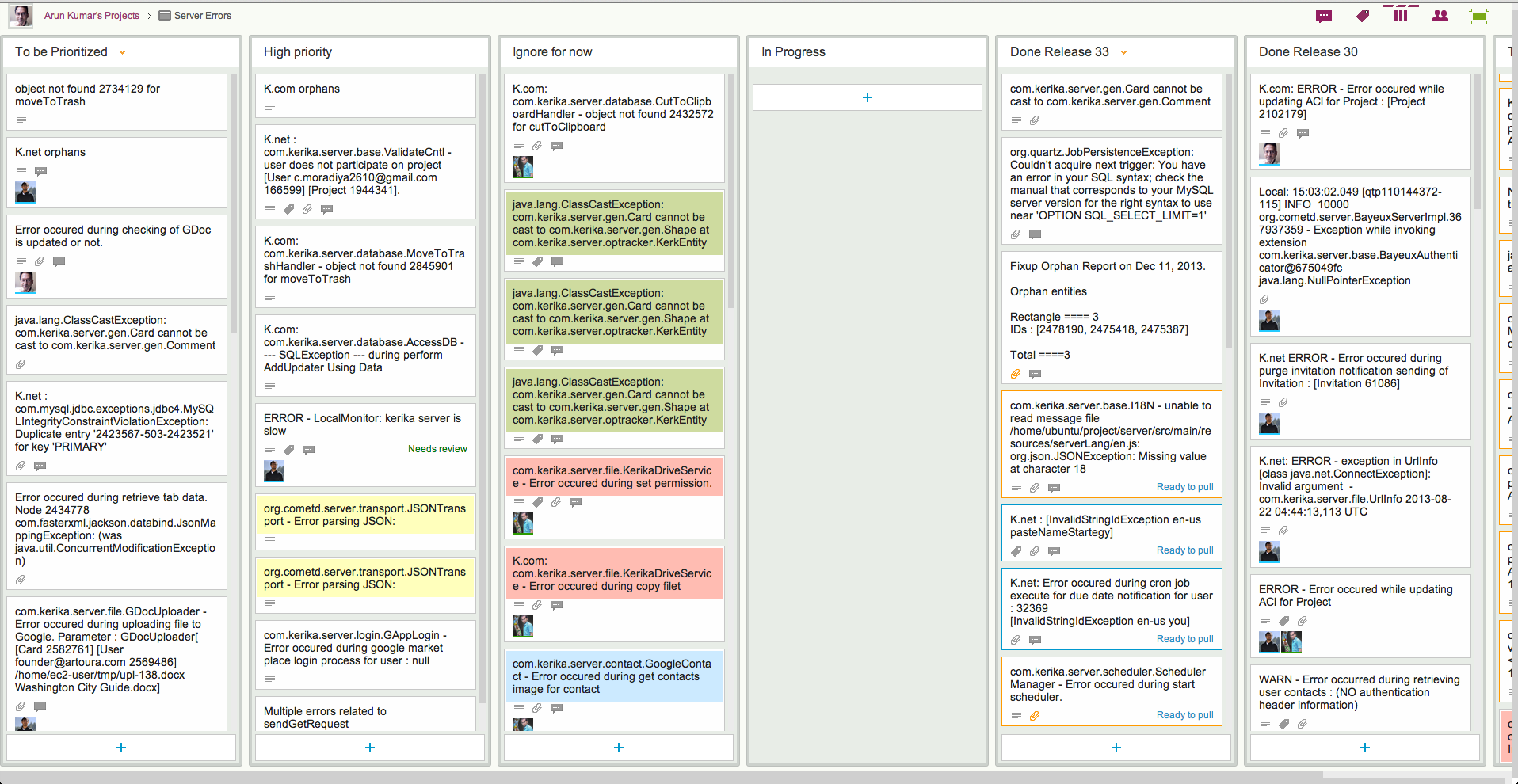
This particular board only deals with exceptions logged on our servers; these are Java exceptions, so the cards may seem obscure in their titles, but the process by which we handle bugs may nonetheless be of interest to others:
Every new exception goes into a To be Prioritized column as a new card. Typically, the card’s title includes the key element of the bug – in this case, the bit of code that threw the exception – and the card’s details contain the full stack trace.
Sometimes, a single exception may manifest itself with multiple code paths, each with its own stack trace, in which case we gather all these stack traces into a single Google Docs file which is then attached to the card.
With server exceptions, a full stack trace is usually sufficient for debugging purposes, but for UI bugs the card details would contain the steps needed to reproduce the bug (i.e. the “Repro Steps”).
New server exceptions are found essentially randomly, with several exceptions being noted in some days and none in other days.
For this reason, logging the bugs is a separate process from prioritizing them: you wouldn’t want to disturb your developers on a daily basis, by asking them to look at any new exceptions they are found, unless the exceptions point to some obviously serious errors. Most of the time the exceptions are benign, and perhaps annoying, rather than life-threatening, so we ask the developers to examine and prioritize bugs from the To be Prioritized column only as they periodically come up for air after having tackled some bugs.
Each bug is examined and classified as either High Priority or Ignore for Now.
Note that we don’t bother with a Medium Priority, or, worse yet, multiple levels of priorities (e.g. Priority 1, Priority 2, Priority 3…). There really isn’t any point to having more than two buckets in which to place all bugs: it’s either worth fixing soon, or not worth fixing at all.
The rationale for our thinking is simple: if a bug doesn’t result in any significant harm, it can usually be ignored quite safely. We do about 30 cards of new development per week (!), which means we add new features and refactor our existing code at a very rapid rate. In an environment characterized by rapid development, there isn’t any point in chasing after medium- or low-priority bugs because the code could change in ways that make these bugs irrelevant very quickly.
Beyond this simple classification, we also use color coding, sparingly, to highlight related bugs. Color coding is a feature of Kerika, of course, but it is one of those features that needs to be used as little as possible, in order to gain the greatest benefit. A board where every card is color-coded will be a technicolor mess.
In our scheme of color coding, bugs are considered “related” if they are in the same general area of code, which provides an incentive for the developer to fix both bugs at the same time since the biggest cost of fixing a bug is the context switch needed for a developer to dive into some new part of a very large code base. (And we are talking about hundreds of thousands of lines of code that make up Kerika…)
So, that’s the simple methodology we have adopted for tracking, triaging, and fixing bugs.
What’s your approach?