I recently offered my thoughts to the Scrum Alliance group on LinkedIn, on the discussion thread on whether
Kanban is a better way to manage support/maintenance work than scrum. I thought you might find it interesting:
Kanban is generally a better model for support/maintenance: these tasks tend to trickle in, so trying to handle them with a conventional Product Backlog is often awkward.
Support/maintenance tasks are also usually unrelated to each other: one bug fix may have nothing to do with another.
This makes for a different metaphor than Scrum/Product Backlog where there is some presumption that user stories and tasks, while perhaps independent, are at least part of a larger product or release theme.
If you did support/maintenance tasks in a Sprint, that Sprint would have no overarching theme which I strongly believe is essential for success with Scrum teams.
And if any team doing support/maintenance with Scrum will quickly realize their Sprints are unlike those of other teams that are doing product development with Scrum.
I would view your questions about swimlanes as arising from a misfitting metaphor: instead of using swimlanes, you would be better off using tags, and then filtering your board as needed to see all support/maintenance tasks related to a particular subsystem or process or person. E.g. “show me all the tasks related to the database schema”.
We use our own product (Kerika) of course, and we do all of our new product development with Scrum Board, and support/maintenance with Kanban boards since Kerika lets you easily have both kinds of boards.
We use multiple tags on each card on both the Kanban and Scrum Boards, so we can filter and search, e.g. “show everything related to our Google Drive integration”.
These filtered views are much more effective and flexible than trying to organize your board with swimlanes, because each card can have multiple tags, whereas with swimlanes a card would be in only one swimlane at any time.
Also, this arrangement gives us flexibility to move from Kanban to Scrum and back: for example, if a support/maintenance card that originally landed on a Kanban board is later deemed to be significant enough to handle as part of product development, we can just cut-and-paste that card from the Kanban board to the Scum Board, and Kerika brings along all the content, history, attachments, chat, etc.
As new bugs/defects are found, add them to the Pending column. This is a holding area for new defects, before they get evaluated and prioritized.
On a daily basis the Product Owner should evaluate items in the Pending column, considering both severity and priority.
Severity is not the same as Priority: if a defect has a serious consequence, e.g. a software bug that causes data loss, then it would have a high Severity rating.
But, some defects show up only rarely. So, you might have a defect with a serious consequence that happens very rarely, or affects very few users. In that case, you may want to reduce its priority.
On the other hand, you may have a defect that is trivial, e.g. a confusing term on a website, but is a real annoyance for everyone. This bug could low severity, but high priority — because fixing it would immediately benefit a lot of your users.
As the Product Owner evaluates each bug, it gets moved to the appropriate column: Fix Immediately, Fix Soon, or Deferred. Within each column, you can further prioritize bugs by moving the most important ones to the top of the column.
Fix Immediately is for the most critical bugs; typically these need to be resolved with a day or two, and the software update may need to be delivered as a hotfix if the normal release cycle is too long.
Fix Soon is for bugs that you definitely need to fix, but which are not super-critical.
Deferred is for bugs that you are not likely to fix anytime soon. (If you don’t plan to fix a bug at all, move it to the Trash.)
As each bug is picked up by a team member, move the card to In Progress, and assign the card to the team member: once someone’s face shows up on the card, it’s clear to everyone that the bug is being worked on, and by whom.
As appropriate, use review processes to review and test the fix before moving it to Ready for Deployment.
Use tags that make sense: we have set up some sample tags for this template; if they don’t make sense, use whatever tags will work best for your team! (There’s a short video on how tags work, attached to this card.)
Along with the hundred styling changes and UI cleanup we are wrapping up, we also took the opportunity to fix around 58 different errors and warnings being reported by our server.
This might sound like a lot, so perhaps a little context is useful:
Kerika is built on top of Google Apps (at least, for now): we use Google’s OAuth service to sign up and sign in people, and we use Google Drive to share files within project teams.
A lot of errors show up as a result of this Google integration, only a fraction of which are solvable from our perspective:
Some errors relate to people from restricted Google Apps domains trying to use Kerika. This happens at least once a week — someone working at a company that has Google Apps for Business tries to sign up for Kerika, but fails because their Google Apps Administrator (typically, someone within their IT department) has prohibited any third-party apps from integrating with their Google Drive.
This is an example of an unsolvable problem — we can’t override the existing protection that this company has set up (and nor would we want to!) so we are going to redirect users to an explanatory page that helps them understand the problem is not with Kerika.
Sometimes Google Apps has outages: when this happens, we can get a cascade of errors on our servers, because these outages are typically intermittent and inconsistent across our user base. Some folks experience problems, others don’t. We are trying to come up with a way to inform people about what’s happening, so they don’t think it’s Kerika that’s busted.
Sometimes Google burps: not have an outage, but experience a fleeting problem with uploading a file. We might get nothing back from Google than a generic “500 error: system not available”.
We have also had problems related to our use of Firefox for the Render Server: Firefox’s latest updates are sometimes less stable than previous ones, and in general Firefox is starting to have a really big footprint in terms of memory usage.
And, finally, we have had our own bugs, just like any other software developer. Some of these have been tricky to find, but as we find them, we squash them.
Kerika is starting to get used in larger organizations more: big global companies, and state and local governments, and as we move into these types of user communities we are finding that people are more likely to create large numbers of projects.
(On average, people create 4-5 projects if they are relatively passive users of Kerika, while more active users — like Project Leaders — might create 30-40 projects over a couple of months.)
To make this smoother, we have been improving the performance of the creation of new projects, as well as the copy-paste function for projects.
It turns out both are closely related, so improving one should help with the other!
A few weeks ago we introduced a new feature: if you included a URL reference in a card’s details, attachments or chat, we would fetch that Web page’s title and show that, instead of just the “raw URL”.
This turned out to be a really helpful feature, and so we are expanding it in our next version by adding logic to handle a wider variety of URLs: the new logic should make it easier to have smart references to URLs show up in your cards even when these URLs are pointing to obscure Web sites, Intranet sites, etc.
We are often asked to advise our users on workflow: it isn’t a primary business of ours – we prefer to build partnerships with process consultants who can provide great services – but the insights we garner from these brief, often unofficial engagements do heavily influence our product design and roadmap planning.
Recently, we have been helping a large industrial company rethink it how it processes requests that come into its various engineering teams, and as a result reorganize its workflow so that there is optimal flow of work across its various design and engineering teams.
Background:
The company is based in North America, and operates on a 24×7 basis all year around, which isn’t unusual in industries that need continual production in order to fully utilize their very expensive equipment. As a result, their “distributed team challenge” was a little unusual: the teams weren’t distributed by location, but by time.
Every aspect of the companies design and engineering functions – which involved highly specialized teams – needed to be replicated in a day shift and a night shift so that work could be handed off continuously throughout the 24-hour cycle. And, that extended to weekends as well: some folks got a “regular weekend” (i.e. Saturday and Sunday off), while others got “staggered weekends” (e.g. Monday and Tuesday off).
Challenges:
In many respects, these teams had collaboration challenges that match those of a US-India distributed team, e.g. a team based on the US West Coast trying to collaborate with a team based in India, and having to deal with a 12.5-13.5 timezone difference (the variation comes from Daylight Savings Time, which isn’t observed in India.)
This 24×7 challenge was relatively straightforward: we have a lot of experience with helping US-India distributed teams work efficiently – based on our own experience, of course.
A different challenge had to do with streamlining the work of the multiple design and engineering teams involved: work requests were coming in from all directions, some through official channels like project planning meetings, and others through unofficial channels like hallway conversations, and in the absence of a clearly defined process to triage new requests, the various teams were feeling randomized.
All these requests were coming in, unfiltered and without any prior review, into a combined backlog that was being used by multiple teams, each of which would normally work independently, often in parallel with each other, and sometimes sequentially (serially) with each other.
Solution:
The solution we proposed was to create another Kerika board that sat upstream of the main engineering board.
This board was used to capture ideas and triage them, and ensure that only complete, appropriate requests made it to the main board’s backlog. This upstream board also helped divert single-team requests to other boards that were created for handling work items that were not cross-team or cross-functional.
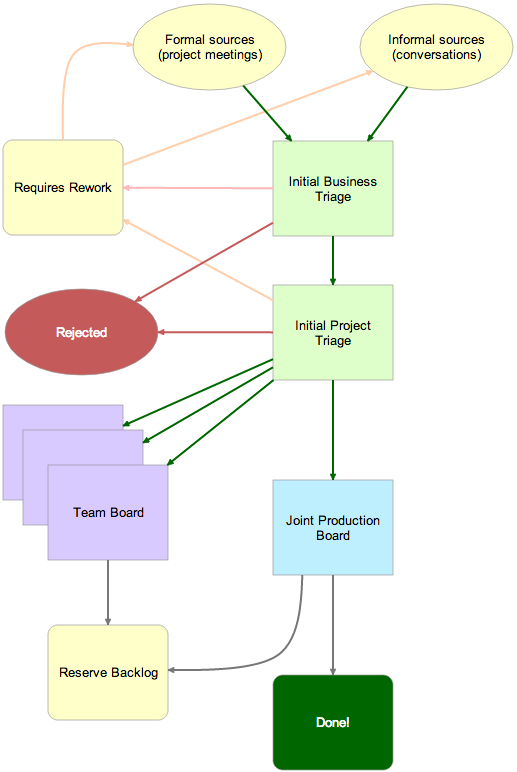
The entire process was captured as a Kerika Whiteboard, as illustrated below:
Workflow for a multi-team industrial company
Let’s take a look at this entire flow, piece by-piece:
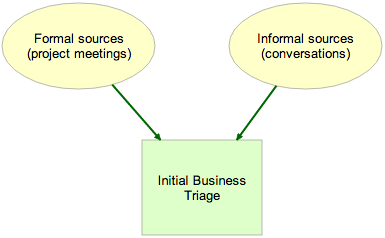
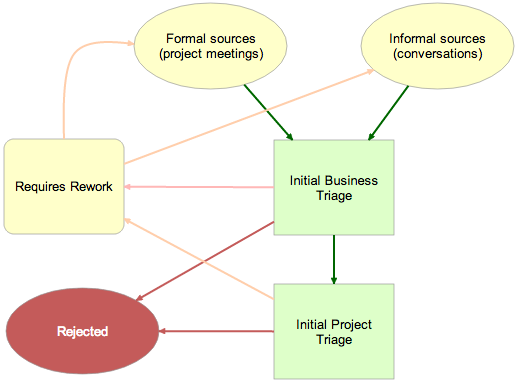
At the top, we have requests coming in: formal requests initiated at project planning requests, and informal requests that originated in stray emails, unexpected hallway conversations, etc. All of these are captured as cards on a Planning Board organized with these columns:
New items :: Under Review :: Accepted by Business :: Accepted by Project :: Needs Rework :: Rejected
We recommended that a single person be designated as Business Owner, and tasked with doing the initial Business Triage of new cards:
Initial Business Triage
The scope of Initial Business Triage is fairly limited: the Business Owner was asked to examine each new card, on a daily basis, and determine whether it qualified as Accepted by Business, Needs Rework, or Rejected.
Enough new ideas came into the organization that a daily review was recommended, and, importantly, the Business Owner was asked to move cards from New Items to Under Review so that people visiting the board at any time (of the day or night!) could see that their requests were in fact being worked on.
And, equally importantly, people could see the overall volume of requests coming into the organization, and adjust their expectations accordingly as to how promptly their own requests might be processed.
To further emphasize transparency and build support for the engineering teams, we recommended that the Planning Board include as many stakeholders as possible, added to the board as Visitors.
As noted above, the goal was to determine whether a card could be Accepted by Business or not, and for this the card needed:
A sufficiently complete description for the work to be handed off to the engineering teams;
To be within the plant’s overall scope and mission (as with most industrial companies, there were several large plants, each with a distinct mission);
Have budget clearance.
This arrangement helped us achieve two important goals
Encourage the promiscuous sharing of ideas, while simultaneously
Ensuring new ideas met a minimum standard of completenessand relevance.
If an idea was within the organization’s scope/mission, but lacked sufficient detail or the appropriate budget approval, it was marked as Needs Rework. And if an idea was clearly outside scope, or had no chance of being funded, it was Rejected.
Another key consideration was to discourage people from setting Due Dates on cards early in the process: delaying the setting of deadlines, until the work reached the teams that would actually commit to delivery, helped preserve flexibility in scheduling and allocating resources.
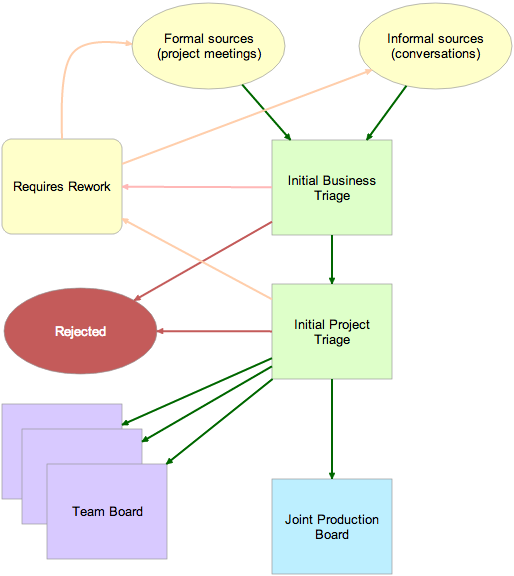
Once the Business Owner did her initial triage of new work, cards were picked up by the designated Project Manager:
Initial PM Triage
The Project Manager worked off the same Planning Board as the Business Owner; she picked up cards that were Accepted for Business. Her goal was to determine the likely impact of each work item, and, critically, to channel the work to either one of the single-team boards, or to the Joint Production board:
Channeling work to the appropriate boards
The Project Manager’s review focused not on business utility (since that was handled earlier by the Business Owner), but rather on identifying whether the work request was likely to affect a single team, or multiple teams.
If the work was likely to affect only a single team, the card was moved to that team’s Kerika board using a simple Cut-Paste operation.
If the work was likely to affect multiple teams, it was moved to the Joint Production Board, which was organized with these columns:
Backlog :: In Progress :: This Week :: Today :: Commission
Tags were used to identify the team involved; since the Joint Production Board typically had hundreds of cards at any point in time, and dozens of team members, this was essential for quick reviews by individual Team Members who wanted to filter out their team’s work items.
As team members became available, they looked first to the Today column to see if anything was marked as Ready to Pull.
If there was nothing in the Today column that was appropriate for the individual person’s skill sets, the person then looked to the This Week column for items that were Ready to Pull.
As an item was taken up by an individual Team Member, she would put her face on the card, to signal to the rest of the team that she had taken ownership of the work.
As work got done, the work product (design documents, engineering plans, etc.) were attached to the cards.
As questions arose, or handoffs were made between team members or entire teams, Kerika’s integrated chat was used to communicate on the cards themselves. (And this is where the 24×7 operation really started to hum!)
Where appropriate Due Dates were set. We had noted earlier that we discouraged people from setting Due Dates at the time they requested new work, to preserve flexibility for the production teams; at this stage it was now appropriate for the teams to make date commitments.
Since all the work that reached the Joint Production Board involved multiple teams (by definition), the card details were updated to reflect the interim deadlines, e.g. the deadline for the Design Team to hand-off something to the Electrical Engineering team.
Once work was completed on a card, it was moved to the Commission column where the final deployment was handled. After that, the card would be moved to Done, and periodically (once a week) the Done column was swept off to another ProjectArchive board.
Occasionally, work would be shunted off to Reserve Backlog: this contained ideas and requests that were plausible or desirable in general terms, but had no realistic chance of being implemented in the short-term.
Workflow for a multi-team industrial company
Key Lessons Learned
Some aspects of this workflow design should be of interest to teams in other industries and sectors:
The use of a Planning Board to act as a way station for ideas and work requests, so that the main boards of the individual teams, as well as the Joint Production Board were not disrupted.
The way station helped ensure that only complete work requests went on to the engineering boards.
The way station encouraged people to contribute ideas and improve them before they were sent to engineering.
Encouraging people to contribute ideas, by making the Planning Board open to a wide group of people who were given Team Member rights (i.e. the ability to add and modify cards).
Separating the roles of Business Owner and Project Manager, so that the business evaluation was distinct from the implementation evaluation.
Separation of individual team boards from the joint production board, so that single-team requests could get processed faster than they would have, if everything had gone through a single pipeline, on a single joint production board.
The user of a Reserve Backlog, to hold on to ideas that the teams might wish to revisit in the future.
What do you think?
We would love to hear your thoughts on this case study!
Every card, every canvas, every board in Kerika has a unique URL.
This makes it really easy to link items together, by using the URL in a card’s chat or description. And, with our latest version, Kerika makes this even easier by showing the title of the other card. Check out this quick tutorial video:
We have added a couple of new features related to dates:
Every card in the Done column, of a Task Board or Scrum Board, will show the date on which the card was marked as done: this makes it easy to see, at a glance, when work was completed on a project.
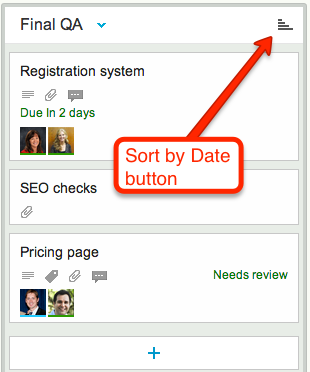
Cards that have dates assigned to them can get sorted by date.
If a column contains any cards with dates assigned to them, a “Sort by Date” button appears at the top of the column:
Sort by Date button
Clicking on this button will sort the cards that have dates:
Only cards with dates are affected: if a column contains some cards that don’t have dates, these are not affected.
You can sort in ascending or descending order.
This is a useful feature for date-driven projects, but if you are working in a pure Kanban or Scrum team, you might want to stick with (manually) sorting dates by priority, which the highest priority items at the top of the column.
Talk to old-timers at Microsoft, and they will wax nostalgic about Windows Server 2003, which many of the old hands describe as the best Windows OS ever built. It was launched with over 25,000 known bugs.
Which just goes to show: not all bugs need to be fixed right away.
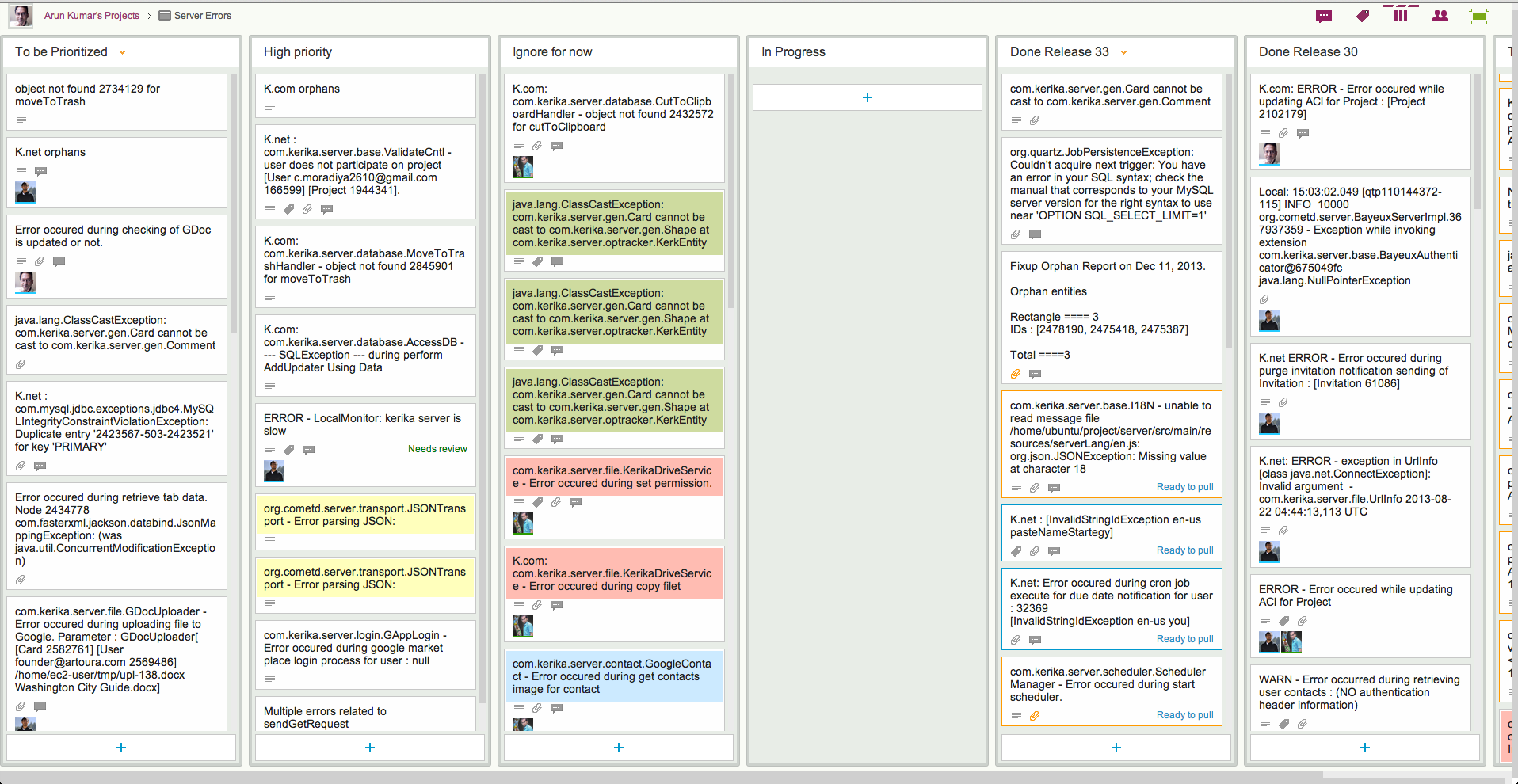
Here at Kerika we have come up with a simple prioritization scheme for bugs; here’s what our board for handling server-related bugs looks like:
How we prioritize errors (click to enlarge)
This particular board only deals with exceptions logged on our servers; these are Java exceptions, so the cards may seem obscure in their titles, but the process by which we handle bugs may nonetheless be of interest to others:
Every new exception goes into a To be Prioritized column as a new card. Typically, the card’s title includes the key element of the bug – in this case, the bit of code that threw the exception – and the card’s details contain the full stack trace.
Sometimes, a single exception may manifest itself with multiple code paths, each with its own stack trace, in which case we gather all these stack traces into a single Google Docs file which is then attached to the card.
With server exceptions, a full stack trace is usually sufficient for debugging purposes, but for UI bugs the card details would contain the steps needed to reproduce the bug (i.e. the “Repro Steps”).
New server exceptions are found essentially randomly, with several exceptions being noted in some days and none in other days.
For this reason, logging the bugs is a separate process from prioritizing them: you wouldn’t want to disturb your developers on a daily basis, by asking them to look at any new exceptions they are found, unless the exceptions point to some obviously serious errors. Most of the time the exceptions are benign, and perhaps annoying, rather than life-threatening, so we ask the developers to examine and prioritize bugs from the To be Prioritized column only as they periodically come up for air after having tackled some bugs.
Each bug is examined and classified as either High Priority or Ignore for Now.
Note that we don’t bother with a Medium Priority, or, worse yet, multiple levels of priorities (e.g. Priority 1, Priority 2, Priority 3…). There really isn’t any point to having more than two buckets in which to place all bugs: it’s either worth fixing soon, or not worth fixing at all.
The rationale for our thinking is simple: if a bug doesn’t result in any significant harm, it can usually be ignored quite safely. We do about 30 cards of new development per week (!), which means we add new features and refactor our existing code at a very rapid rate. In an environment characterized by rapid development, there isn’t any point in chasing after medium- or low-priority bugs because the code could change in ways that make these bugs irrelevant very quickly.
Beyond this simple classification, we also use color coding, sparingly, to highlight related bugs. Color coding is a feature of Kerika, of course, but it is one of those features that needs to be used as little as possible, in order to gain the greatest benefit. A board where every card is color-coded will be a technicolor mess.
In our scheme of color coding, bugs are considered “related” if they are in the same general area of code, which provides an incentive for the developer to fix both bugs at the same time since the biggest cost of fixing a bug is the context switch needed for a developer to dive into some new part of a very large code base. (And we are talking about hundreds of thousands of lines of code that make up Kerika…)
So, that’s the simple methodology we have adopted for tracking, triaging, and fixing bugs.
One great advantage of a visual task board like Kerika is that it is a really fast and easy way to identify bottlenecks in your workflow, far better than relying upon burndown charts.
Here are a couple of real-life examples:
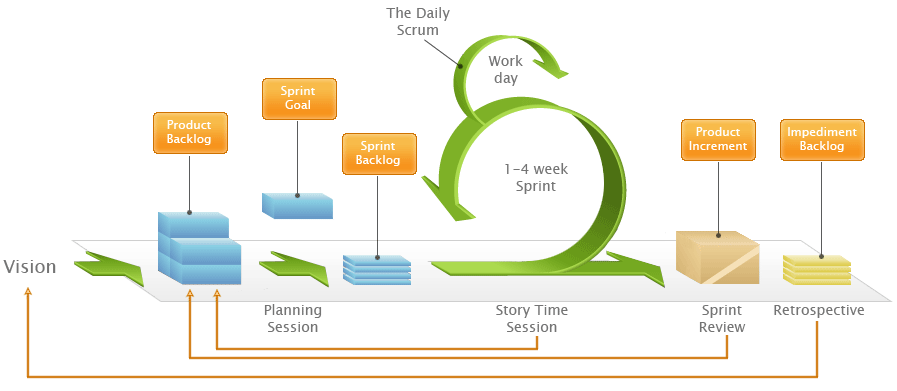
Release 33 and Release 34 are both Scrum iterations, known as “Sprints”.
How Scrum works
Both iterations take work items from a shared Backlog – which, by the way, is really easy to set up with Kerika, unlike with some other task boards ;-) And for folks not familiar with Scrum, here’s a handy way to understand how Scrum iterations progressively get through a backlog of work items:
We could rely upon burndown charts to track progress, but the visual nature of Kerika makes it easy to identify where the bottlenecks are:
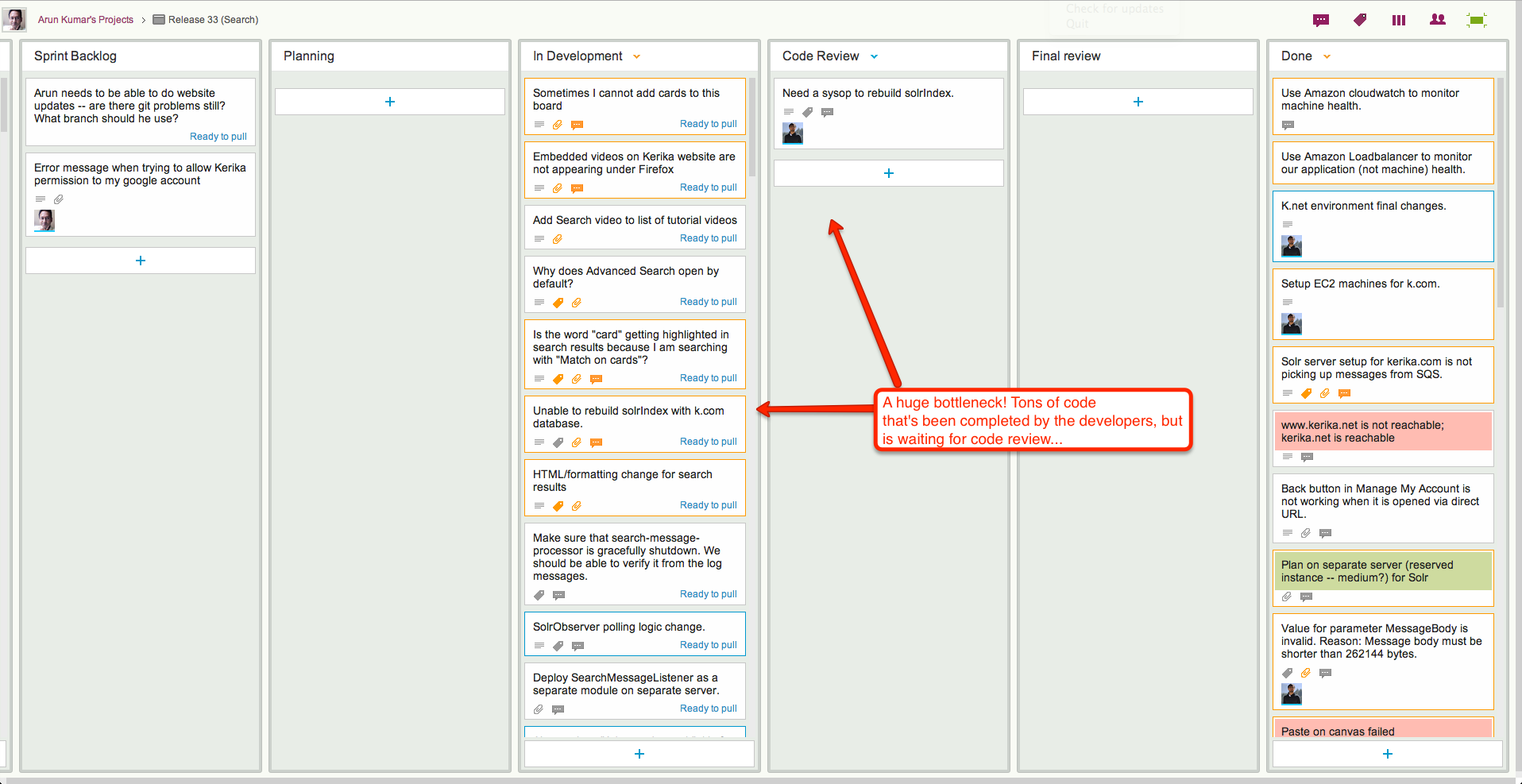
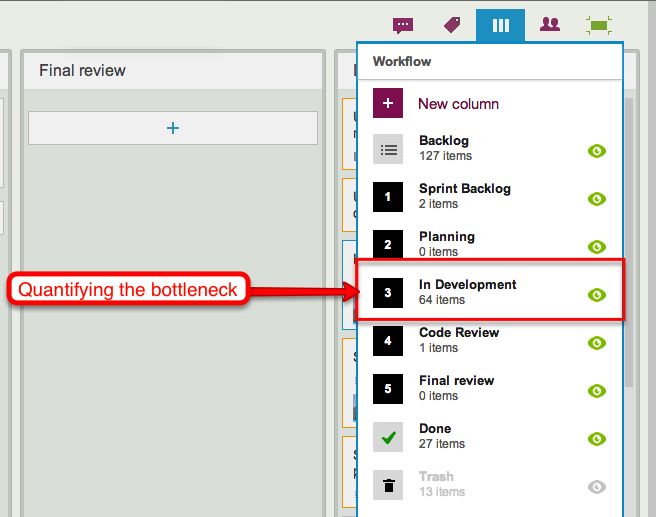
In Release 33, the bottleneck is obviously within the Development phase of the project:
Release 33: a bottleneck in Development
When we take a look at the Workflow display, it’s easy to quantify the problem:
Quantifying the bottleneck in Release 33
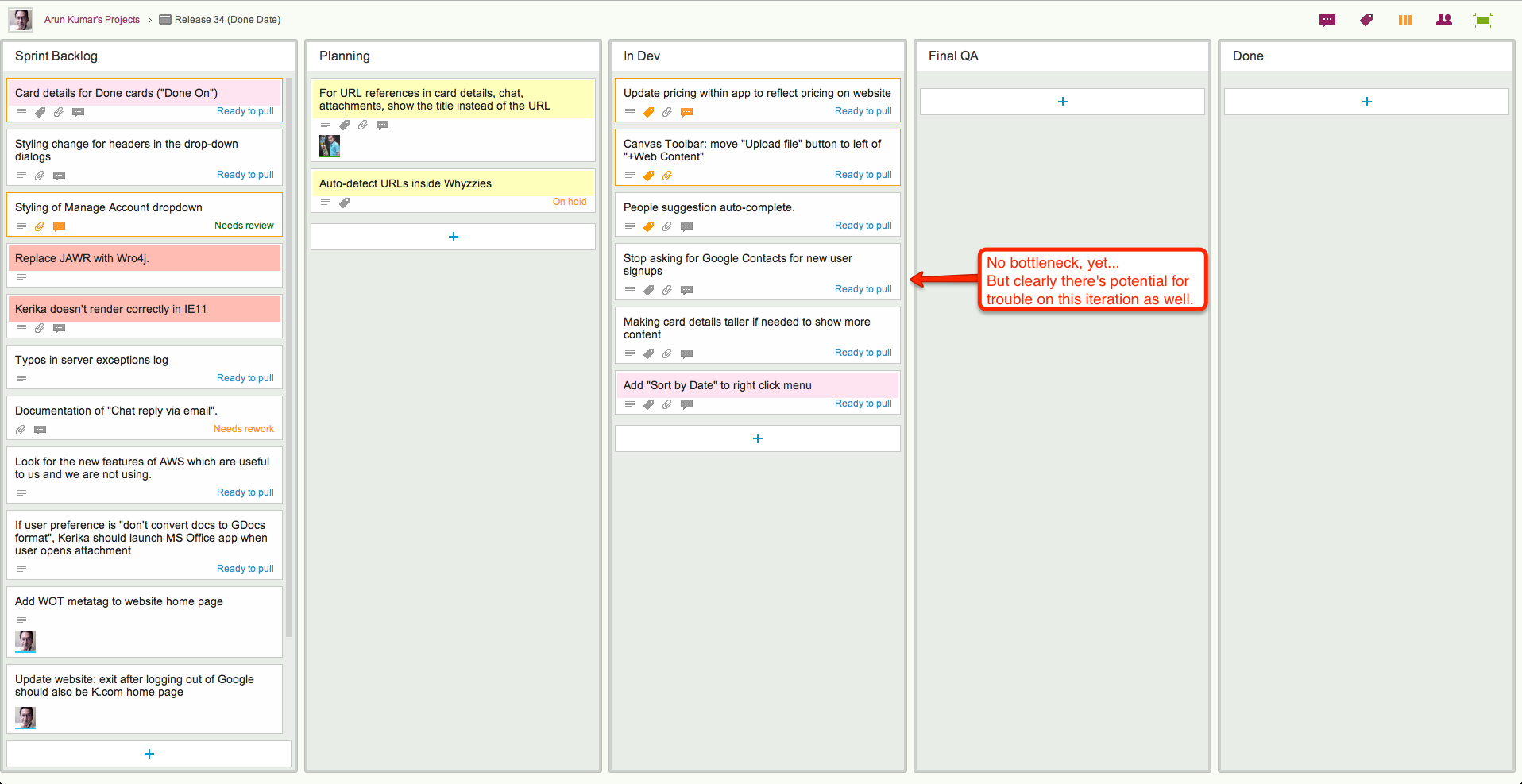
By way of contrast, here’s Release 34, another Scrum iteration that’s working off the same Backlog:
Release 34: a smaller bottleneck
This iteration doesn’t have the same bottleneck as Release 33, but warning signs are clear: if we can’t get our code reviews done fast enough, this version, too, will have a develop a crunch as more development gets completed but ends up waiting for code reviews.
In both cases, Kerika makes it easy to see at a glance where the bottleneck is, and that’s a critical advantage of visual task boards over traditional Scrum tools.