We had always treated our customers data as confidential, and have never shared that with anyone else. At the suggestion of one of our users, we have updated our Terms of Use to make this a written commitment.
We have added Section VI to our Terms of Use:
“Confidential Information” means information identified by you as confidential at the time of disclosure or that a reasonable person would consider confidential due to its nature and any confidential, proprietary, or privileged information disclosed while creating or modifying the Kerika boards.
Kerika shall preserve the confidentiality of your Confidential Information and treat such Confidential Information with at least the same degree of care that Kerika uses to protect its own Confidential Information, but not less than a reasonable standard of care.
Kerika will use your Confidential Information only to exercise its rights and perform obligations under these Terms. Confidential Information will be disclosed only to those employees of Kerika with a need to know such information in connection with Kerika’s use of the Confidential Information in accordance with these Terms.
Kerika shall not be liable to you for the release of Confidential Information if such information is divulged pursuant to any legal proceeding or otherwise required by law, provided that, to the extent legally permissible, Kerika will notify you promptly of such required disclosure. Kerika agrees to promptly notify you of any unauthorized access to or disclosure of the Confidential Information.”
We have been lax in updating this blog, sorry, but not lax at all in working on improving Kerika, especially for mobile browser users. We are also getting close to releasing our mobile app, which will contain the same functionality as you get today when you access Kerika on a phone, but it will be packaged as a traditional-looking app for folks that want an icon on their desktop.
Here’s a short list of things that have been improved and added in the past few months:
For mobile browsers
There’s more of the desktop functionality now available on phones as well, including:
Managing the columns on a board: adding new columns and changing existing columns so you can customize the workflow of each board.
Drag-and-drop to reorganize items within lists: the order of columns, the order of tasks and attachments within a card, etc.
The Home Page (which we will be calling the Explorer, in anticipation of other anchor pages that we will roll out soon) has more complete abilities to manage your boards, templates, archive and trash, including favoriting items.
The Contact Us (to get help) feature has been implemented.
The Manage Profile feature has been implemented, including changing your name, photo and password.
The My Preferences feature has been implemented, and redesigned for both the desktop and mobile to make this easier to use.
We have made performance improvements across the board, although we continue to push the boundary on this. (One of our own boards regularly has over 700 cards so we are our toughest users and testers.)
A bunch of styling tweaks to help improve usability and readability, and there’s always going to be more coming in the future.
For desktop users
A bug that caused Views to not be properly updated for some users has been fixed.
When you switch from your current board to another open board and then return to the first board, Kerika will remember the scroll position so you can pick up where you left off without any delay.
For both mobile and desktop
The Preferences section has been reorganized to make it easier to use.
We have made some tweaks to make it easier to sign up, change passwords, etc. (And there’s more coming on this front.)
Users who signed up after getting an invitation from someone else will start off just having access to the boards and accounts they were invited to; now they can create their own account as well if they want to use Kerika for private work using the same email address.
Fixed some issues with our billing system that caused us to be underpaid in a few instances. We are going to do a big overhaul of our billing system later this year (hopefully) to make it easier for both Kerika and our customers.
We have started purging defunct accounts: users whose email addresses don’t seem to be valid anymore.
We are not doing this in a hurry, but instead are trying to be methodological about it: if someone’s email bounces, and we see they haven’t logged in during the past 6 months, we are going to assume this user doesn’t exist within that organization anymore, i.e. has probably left the company where they were previously working.
(The 6 months of no-activity helps us avoid temporary email problems, such as when someone’s email server is down for a day.)
Also getting purged are new users with invalid emails: this can happen when an existing user mistypes a coworker’s email address at the time they invite people to join their teams.
An account is created at the time someone initiates the invitation, but if we find the email associated with that account is bouncing, we will delete that account.
An updated primer, showing for organizations that are using G Suite (formerly known as Google Apps for Business) can install and authorize Kerika for their domains:
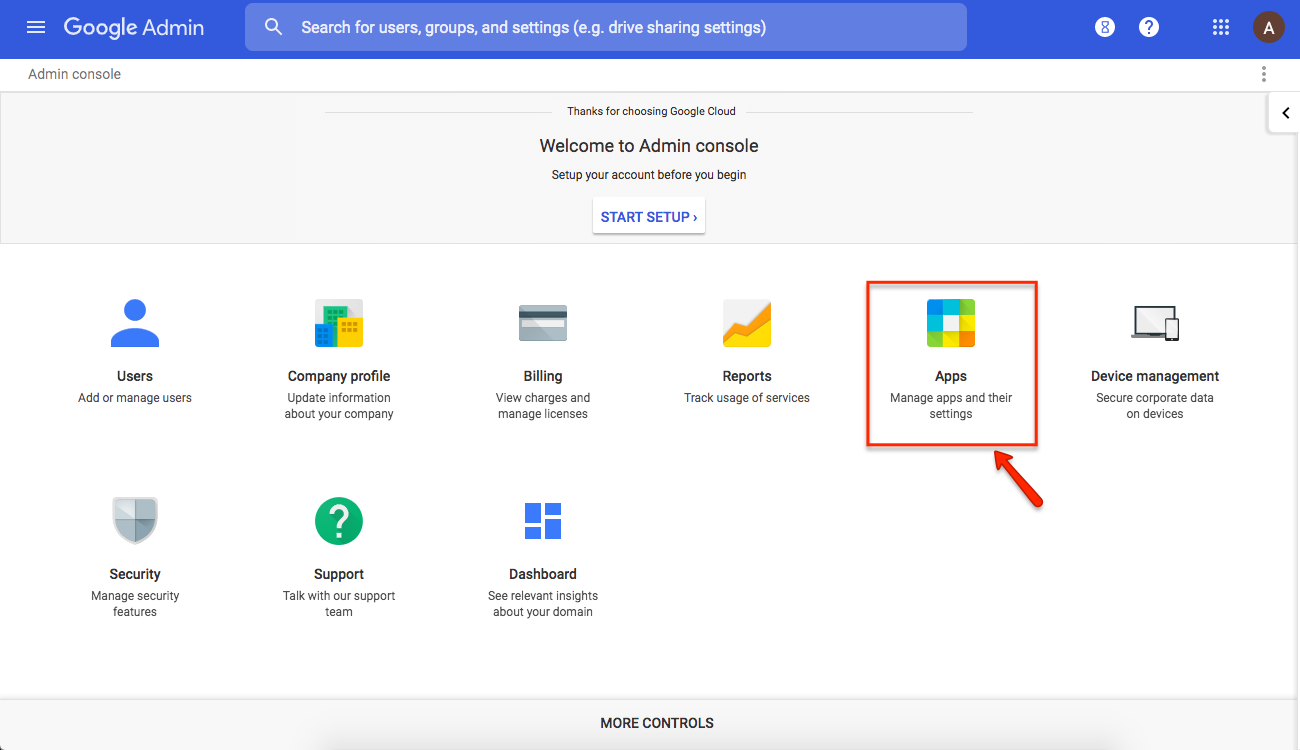
The organization’s Google Admins (and there’s usually more than one such person) can view their Google Console at https://admin.google.com: click on the Apps button.
Start at the Google Admin Console
2. This will take you to all your Google-related apps.
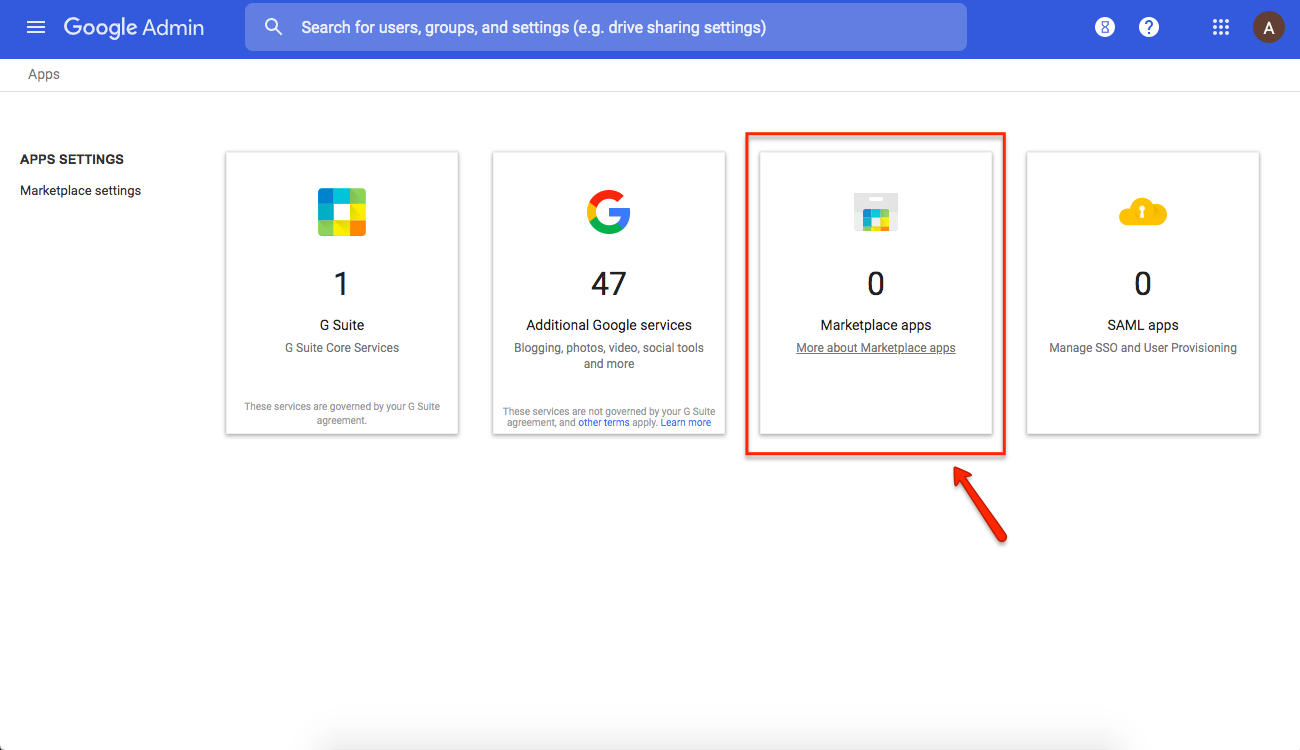
Kerika falls into the Marketplace Apps category, so click on that button.
Go to Marketplace Apps
(All the other buttons are for apps from Google itself; Marketplace is where third-party vendors like Kerika show up.)
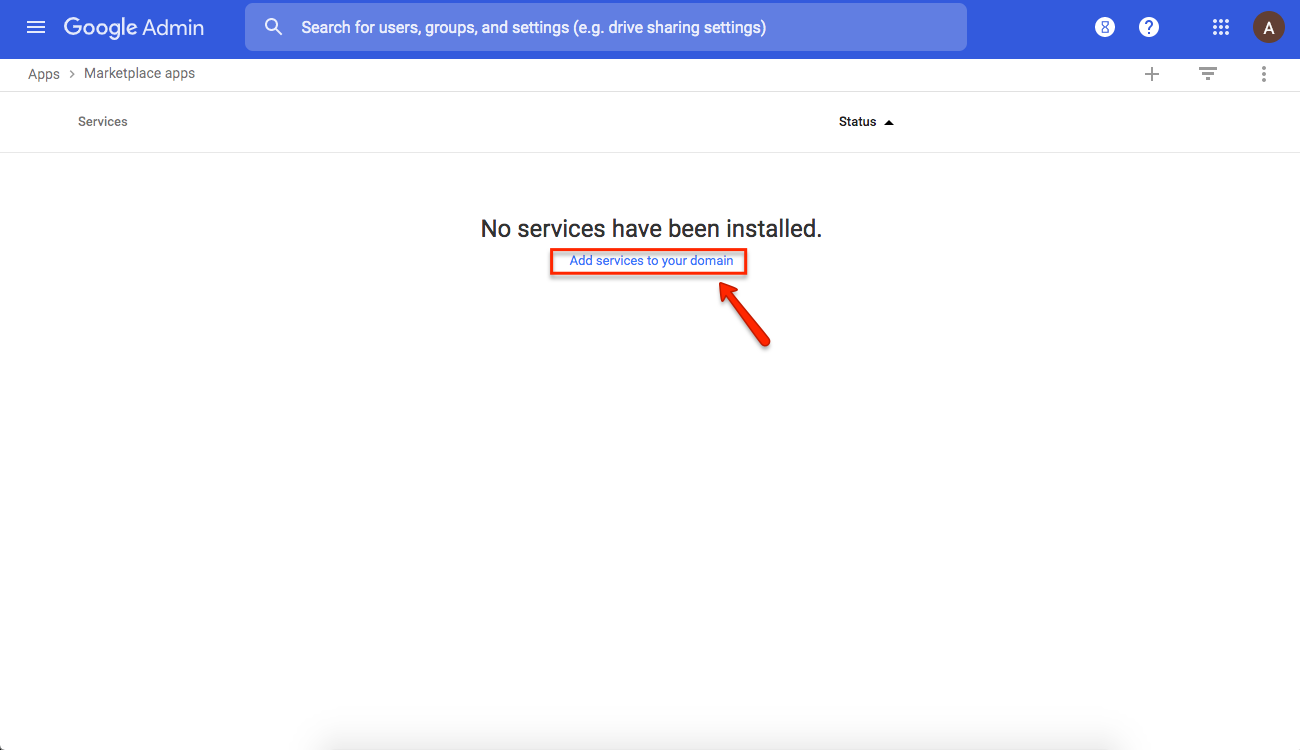
3. Click on Add Services
This will take you to the G Suite Marketplace
Add services to your domain
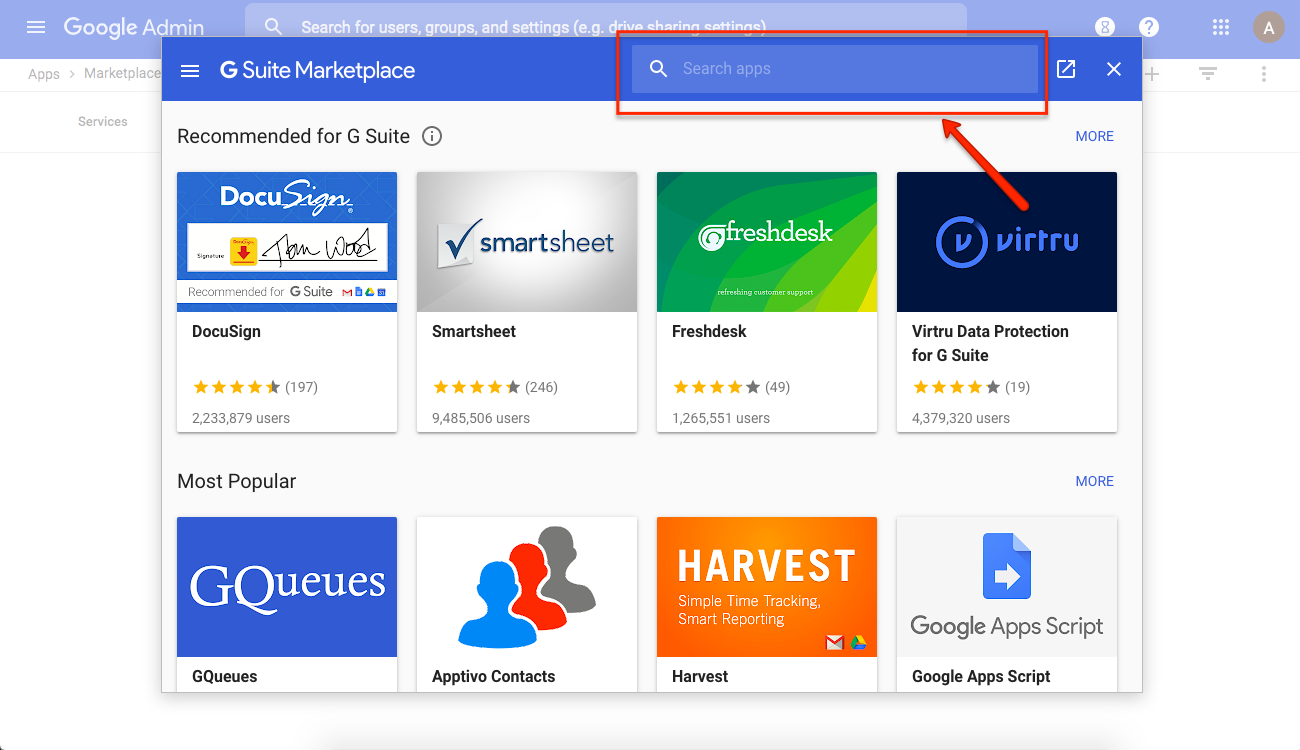
4. Search for Kerika
It would be nice if Kerika showed up right away, but you need to search for it in the box shown below:
Search for Kerika
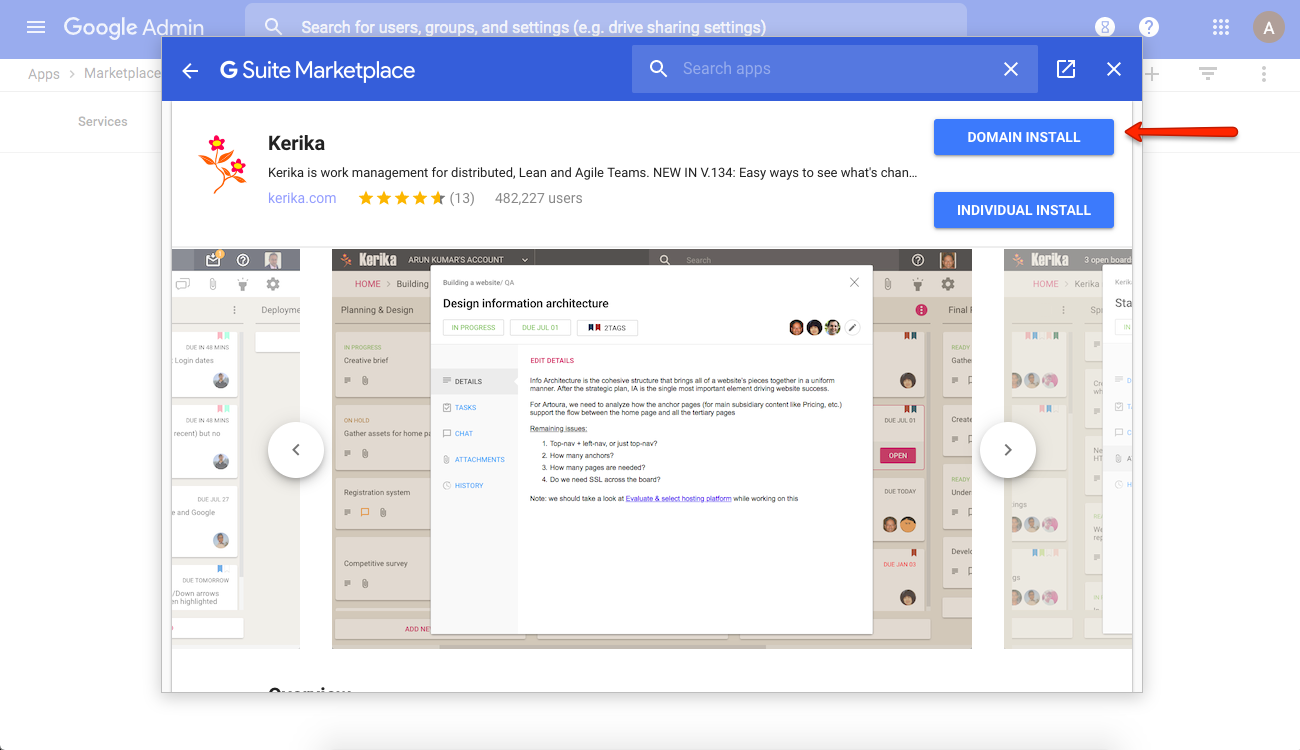
5. Select Domain Install
The Domain Install option will allow everyone in your organization to use Kerika:
Click on Domain Install
6. Accept the Terms
Accept the Terms
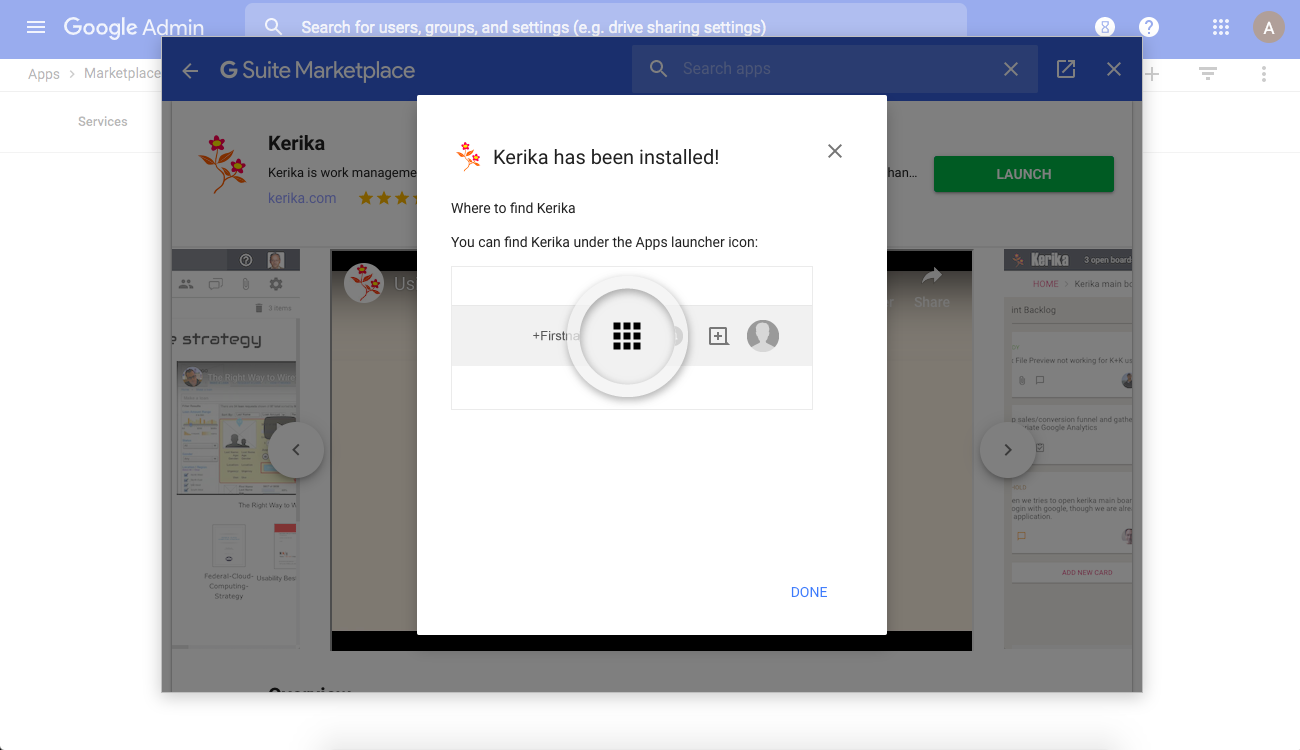
7. Success!
Kerika is now installed for your organization’s use:
A free Academic Account is intended to help students and educators get more done with their teams: a free Account has all the features of Kerika, but is limited to a maximum of 10 Team Members working on boards owned by that Account.
Every user can set up their own Account, so effectively it is possible for a very large group of students and educators to use Kerika free for their academic work!
If you are interested in getting Kerika for your (nonprofit) school or college, please get in touch!
Along with our recent (and ongoing) effort to update all the Kerika tutorial videos, we will be rolling out a new system of sending welcome emails to new users.
These emails will come once a day for the first 10 days or so (it depends upon how many tutorial videos we end up creating), and each email will include a link to a specific tutorial: e.g. how files are managed in Kerika, or how teams can be set up.
Our goal is to help new users learn about core features of Kerika as quickly as possible, over the first couple of weeks of their usage.
These emails are distinct from the notifications that might be generated through your normal usage of Kerika, such as (optionally) getting a task summary sent at 6AM.
A simple unsubscribe system is also being rolled out in conjunction with these emails: if a user doesn’t find these tutorials helpful, they can stop receiving them.
Views are unique to Kerika: no other work management system provides such an easy way to see what matters, across all the boards you are working on.
These Views make it easy for organizations to really scale up their use of Kerika across multiple projects and many ongoing projects at the same time.
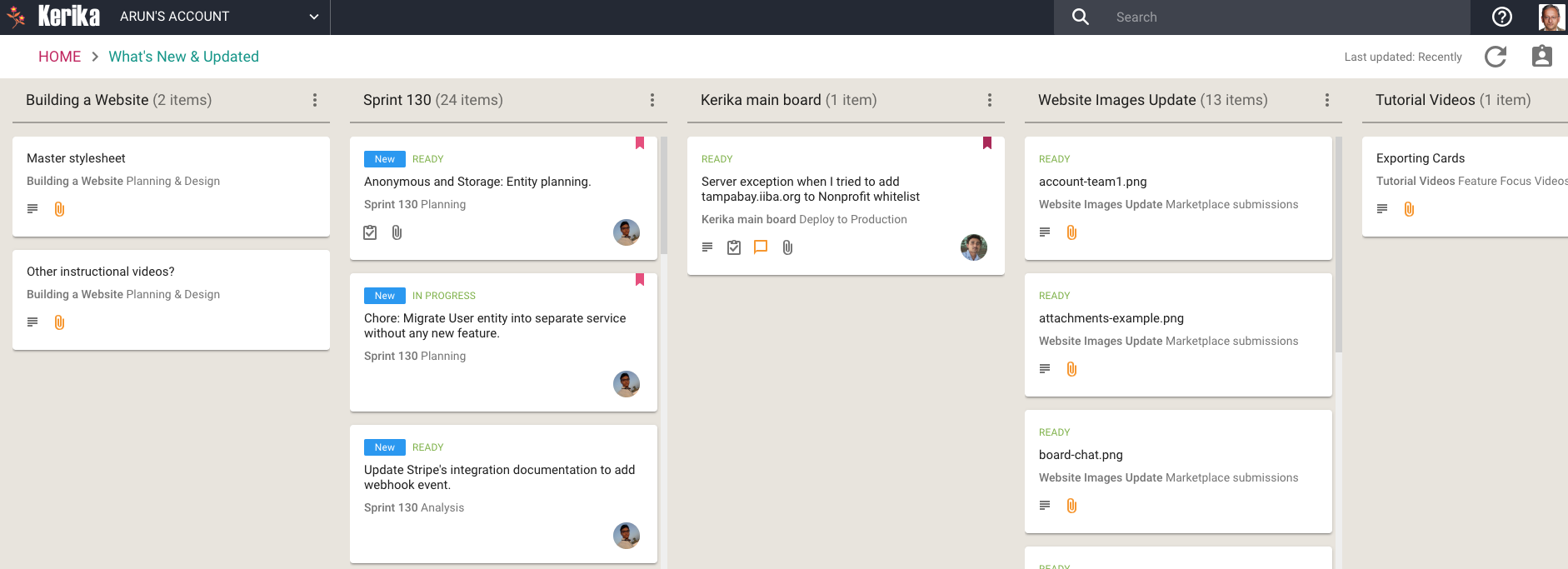
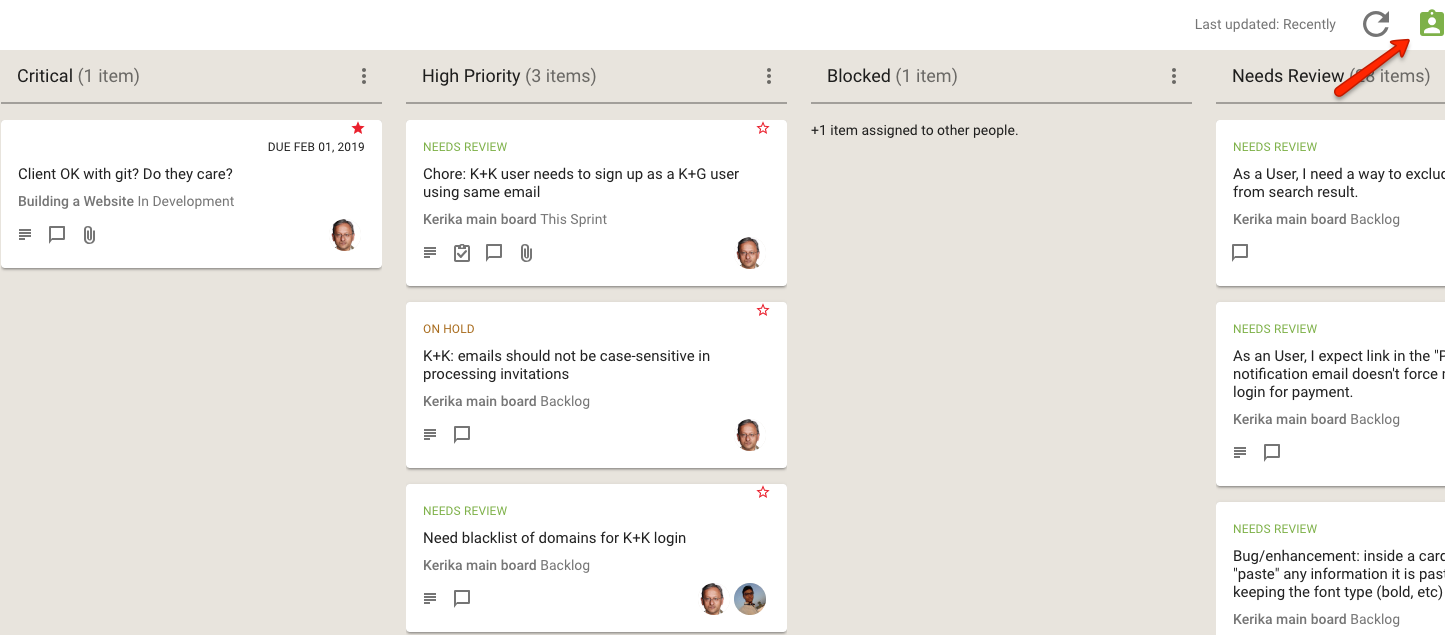
We have now added a very useful new View: What’s New and Updated. As you might guess from the name, this View lets you catch up on everything that’s new and changed, across all the boards you are working on — as a Board Admin, Team Member or Visitor.
What’s New and Updated (click for a larger image)
This View can work very effectively as a Dashboard for managers who need to keep track of many different boards, all working at the same time: instead of constantly revisiting each board one-by-one, this View is a simple, comprehensive way to see everything that’s changing across all your boards.
The updates are shown in Kerika’s unique “heads-up” notification style: the blue New tags highlight cards that have been newly added to your boards (that you haven’t opened yet), and the orange highlights show you precisely what’s changed on your old cards.
The new and changed cards are sorted into columns, with each column containing all the new and changed items within a particular board. The newest changes appear at the top of a column, and if a board has nothing new to report, the corresponding column is not shown (so your View doesn’t get cluttered up.)
(Cards that are moved to the Done or Trash columns on a board are not included in the View, to help avoid getting the View cluttered.)
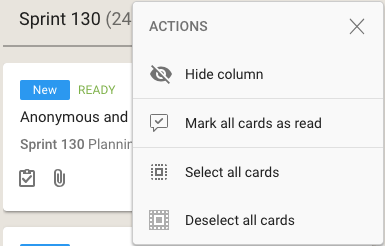
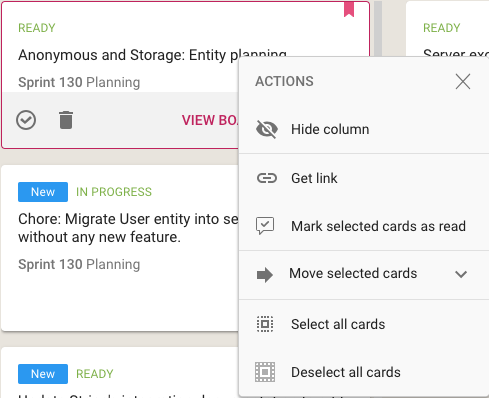
As with all Views, it’s easy to operate on all the cards within a column, by selecting the Column Actions button that appears on the top of each column:
View options
The Mark All Cards As Read action is useful if you want to ignore everything that’s going on in a particular board, e.g. when you have just returned from a status meeting where you got fully briefed on what’s happening on a particular board.
Another way to temporarily ignore individual boards is to Hide Column: this collapses the column from the View, and let’s you focus more intently on the handful of boards you care most about.
Selecting a card in this View lets you open the card within the View itself, or to open it on the board where the card actually sits:
View card
(Sometimes it’s easy to deal with cards just by themselves; sometimes the View Board action is more helpful, if you want to be sure you understand the full context in which a card changed.)
Using your mouse’s right-click action will also bring up a bunch of useful actions for that card:
Mouse actions
In addition to all the other actions you can perform on cards, you also have the option to get the URL (address) of card using the Get Link action. Every cards, every canvas and every board in Kerika has a unique address, and using these URLs anywhere on a board, e.g. in the board’s details or chat, will automatically set up a link between the two cards.
When you mark a card as “read” on this View, it remains on the View until you click on the Refresh button (shown at the top-right corner of the View).
And, as with all Views in Kerika, the What’s New and Updated View includes the “For Me” toggle button on the top-right corner: clicking this will quickly filter the View to show you just those items that are personally assigned to you.
For Me toggle (click for larger image)
This feature is available to all our users, just like every other feature in Kerika: it doesn’t matter whether you are still in your 30-day free trial, you are working on the free Individual Plan, or are benefiting from Kerika’s free Academic and Nonprofits Accounts. Everyone always get the same Kerika goodies :-)
We have offered free accounts to small nonprofits and schools/universities from the very beginning of Kerika’s existence, but this was always on an ad hoc basis: someone would occasionally ask us for a free account for their school or nonprofit team, and we would agree.
Looking back, we found that we agreed to almost 99% of all the requests that ever came to us: the only situations where we turned someone down were
When we couldn’t figure out what the nonprofit was doing, or even whether it really existed. (Having a domain for your school/nonprofit really helps, even if it is not in English.)
When the school was for-profit, (We dodn’t see why we should subsidize for-profit organizations.)
When the organization was essentially a governmental entity that was getting funded through public money in a normal way.
With these caveats aside, we have tried to be very generous and helpful for small organizations that are doing philanthropic work, or are schools.
But our old process for dealing with these requests was really haphazard, and when we implemented our new billing system and improved account management features, we also made it easier for us to grant nonprofit status to a much larger group of organizations, providing they are small teams.
Our new process makes everything much easier for schools and nonprofits: we are whitelisting entire domainsso that everyone from that domain who signs up automatically gets a free Academic & Nonprofit Account.
This means that only person ever needs to make a request on behalf of a school or university: if that gets approved, we will approve it for everyone from that school/university.
With a free Academic/Nonprofit Account you can have up to 10 people working on boards owned by that account: it doesn’t matter how many boards you have, or how big these boards are.
If you need more than 10 people, you will need to sign up for a Professional Account, which is $7 per user, per month (normally billed annually, as $84 per user).
Here’s a partial list of schools and universities we have already whitelisted for free service:
Adler Graduate Professional School, adler.ca
American Quality Leadership & Educational Management, aqlem.com
Arizona State University, asu.edu
Austin Community College, austincc.edu
Australian Pacific College, apc.edu.au
Bethlehem University, Palestine, bethlehem.edu
Boston University, bu.edu
California State University, Fullerton, csu.fullerton.edu
Campbell University, campbell.edu
Carnegie Mellon University, cmu.edu
Catholic Education Diocese of Wagga Wagga, Australia, ww.catholic.edu.au
Clemson University, clemson.edu
Cochise College, cochise.edu
Coconino Community College, coconino.edu
College Euroamericano, Monterrey, colegioeuro.edu.mx
College La Grange du Bois, Savigny Le Temple, clg-la-grange-du-bois-savigny-le-temple.fr
Colorado State University, colostate.edu
Cornell University, cornell.edu
Crefito-3, Sao Paulo, crefito3.org.br
Drew, drew.edu
Duke University, duke.edu
Edmonds Community College, edcc.edu
Escuela de Educacion Secundaria Tecnica No. 5 de San Martin, Argentina, galileo.edu.ar
Everett Community College, everettcc.edu
Faciplac, Brasilia, faciplac.edu.br
Fundacion de Estudios Superiores Universitarios, Medellin, fesu.edu.co
George Fox University, georgefox.edu
Humboldt State University, humboldt.edu
ICDL Colombia, icdlcolombia.org
Iḷisaġvik College, ilisagvik.edu
Indiana University, iu.edu
Institucion Universitaria Colegio Mayor del Cauca, Colombia, unimayor.edu.co
Instituto Potosino de Investigacion Cientifica y Technologica, Mexico, ipicyt.edu.mx
Instituto Superior de Ciências Económicas e Empresariais, Cape Verde, iscee.edu.cv
Instituto Superior de Formacion Docente Salome Urena, Dominican Republic, isfodosu.edu.do
Iowa State University, iastate.edu
Kalamazoo Valley Community College, kvcc.edu
Kirtland Community College, kirtland.edu
Kuruwi, Cabo San Lucas, kuruwi.edu.mx
Lane Community College, lanecc.edu
Macquarie University, mq.edu.au
Maricopa Community Colleges, maricopa.edu
Michigan Tech University, mtu.edu
Mid Michigan College, midmich.edu
Milwaukee Area Technical College, matc.edu
Mount Holyoke College, mtholyoke.edu
Mount Wachusett Community College, mwcc.edu
Mundo Sin Fronteras, Oaxaca, sinfronteras.edu.mx
National Kaohsiung University of Science and Technology, Tawian, kuas.edu.tw
National Taiwan University of Science and Technology, ntust.edu.tw
Newman University, newmanu.edu
North Carolina State University, ncsu.edu
oc.unlv.edu
Oregon Health Sciences University, ohsu.edu
Ośrodek Szkolenia, Krakow, straz.edu.pl
Paul Cuffee School, paulcuffee.org
Philadelphia College of Osteopathic Medicine, pcom.edu
Thanks to a longtime user from Poland, we discovered — and fixed — a bug that crept into one of our recent feature enhancements, where items couldn’t be permanently deleted from the Trash column on Task Boards and Scrum Boards.