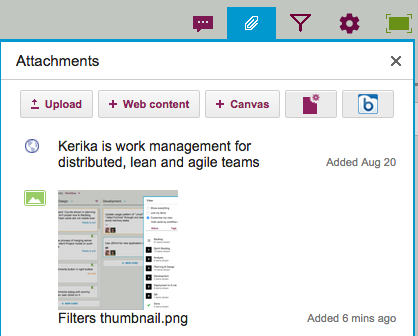
If you use the “file picker” that’s built into Kerika to add an existing Google Drive or Box file to a card, canvas or board — for a Task Board, Scrum Board or Whiteboard — you will see a message that says the file is being copied.
This is the file picker:
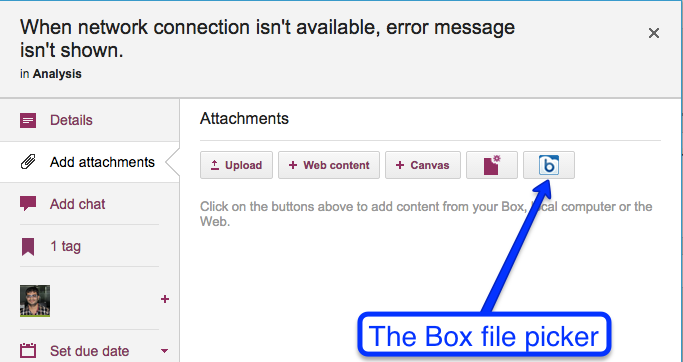
Clicking on the File Picker button brings up the File Picker dialog:
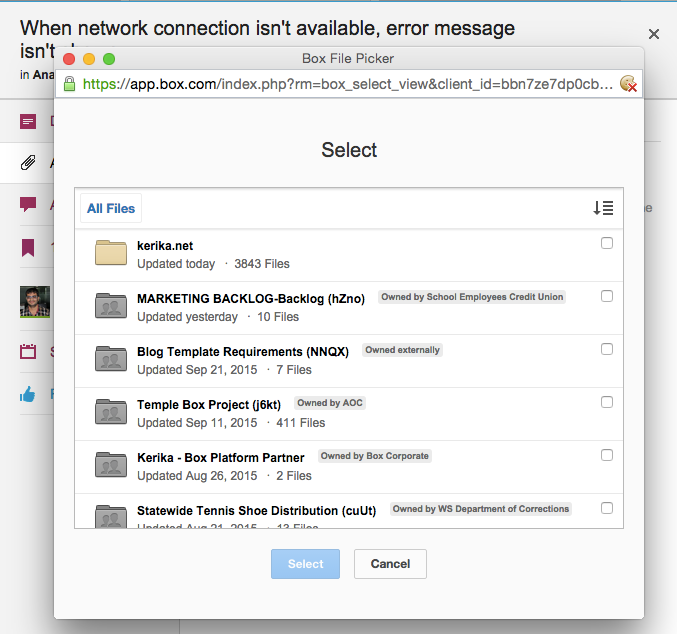
And this is the “copying…” message that’s shown.
So, what’s happening?
Well, Kerika stores all your Kerika-related files in a set of special folders within your Google Drive or Box account, if you are using Kerika+Google or Kerika+Box, and these are organized neatly into folders corresponding to each of your boards.
Here’s what the folders in your Box account look like (you can learn more by reading about how Kerika integrates with Box):

It’s a similar structure if you are using Kerika with Google:

Keeping all the Kerika files together in a set of related folders makes things cleaner for you: when you look at your Google Drive or Box Account, you know exactly what’s being used by Kerika, and what’s other stuff.
And this is why we make a copy of your existing Google Drive or Box file when you use the File Picker: it enables us to put a copy into your Kerika-specific folders, where it is easier to share with the rest of your project team.