A ton of bug fixes, most of them so obscure that no end-users ever spotted them, but since we track our error codes seriously we make sure we fix stuff that no one even knew fixing. Some of the bug fixes are truly obscure, here’s a few from our latest version that’s easier to explain:
- There were some problems related to how our iOS app was updating that were a result of Apple deciding not to support Progressive Web Apps anymore. (Thanks for nothing, Apple.)
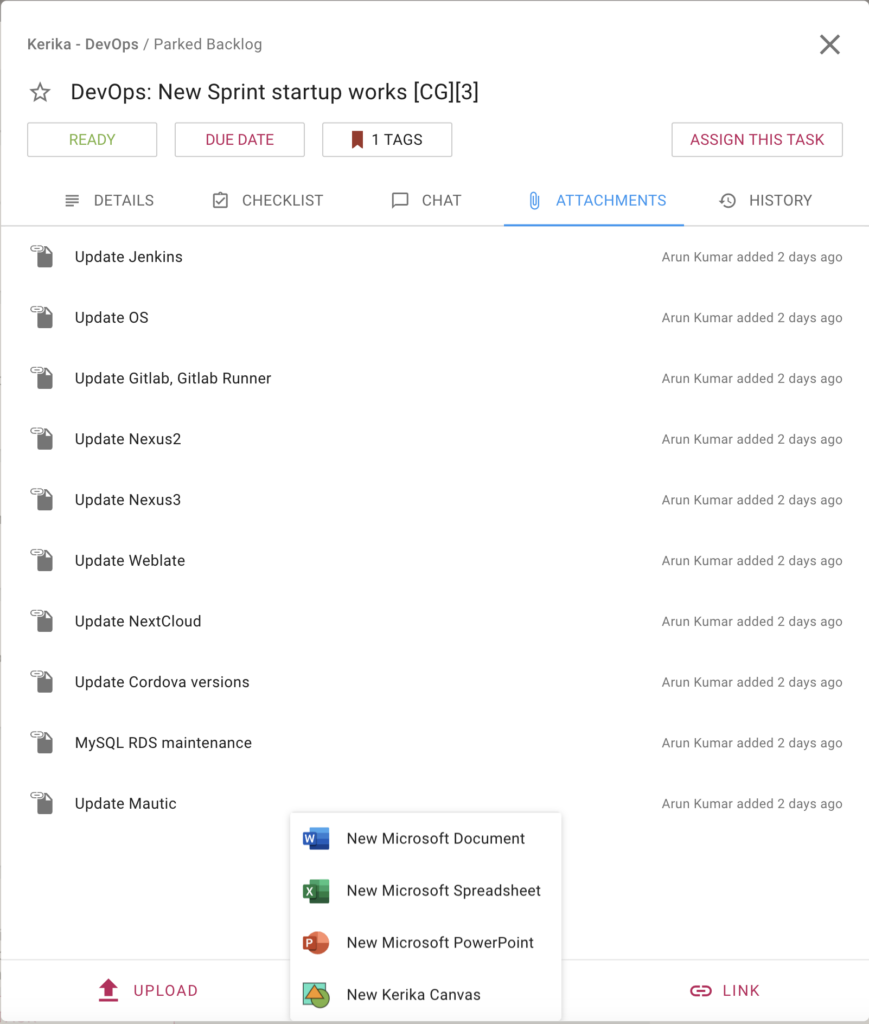
- When a person renamed a file attached to a task or board, the file was appearing as having unread updates (orange highlight) to the user who made the change.
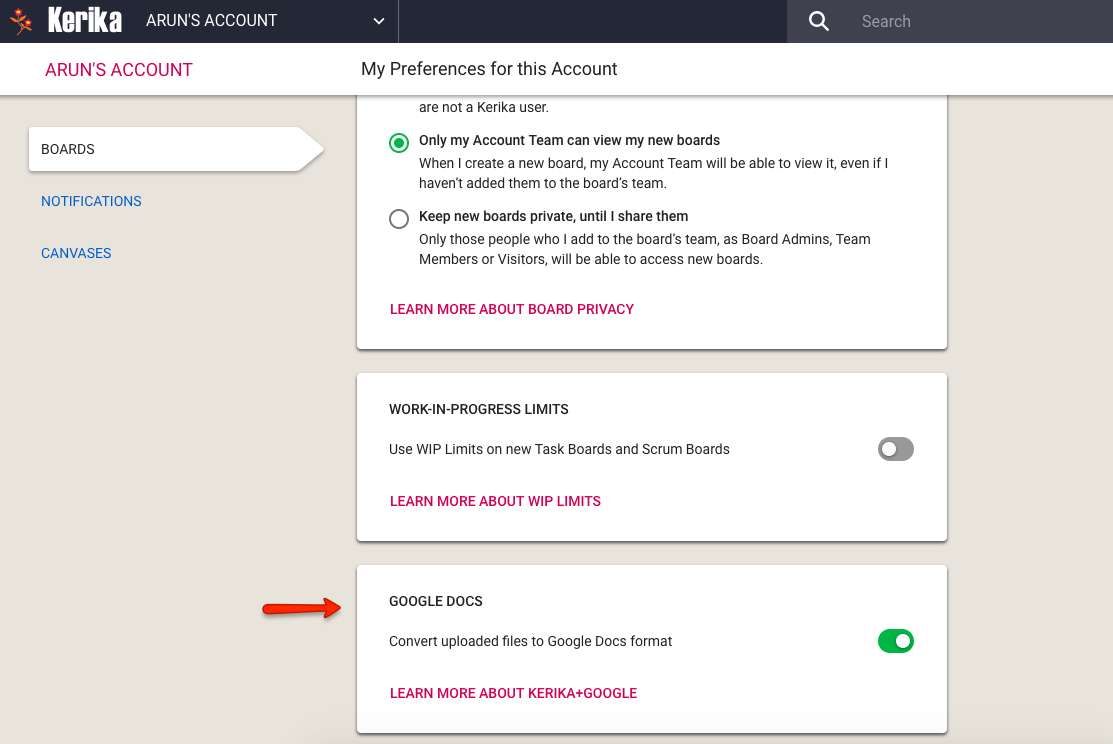
- For our Kerika+Microsoft users, we needed to make sure the correct OneDrive icons were appearing where files were attached to tasks and boards.
- Also for our Kerika+Microsoft users: OneDrive files are better support for users of our Whiteboards feature.
- When a text field could potentially be auto-filled using the browser’s saved values, if a user selected a saved value it wasn’t displaying properly. (Thanks to a breaking change in one of Chrome’s many, many updates — seriously, why are they releasing new versions every week?)
- Dates shown for non-English users will now appear in the locally selected languages.
- If a user opened a task on the mobile apps that had been found by doing a search, editing the task’s title was showing HTML characters.
- Handling situations better where two people were making changes to the same task at the same time: users are warned if someone else has made changes that would get overwritten if they saved their own changes.
- Improvements in the new user experience: this is, frankly speaking, a never-ending quest for us!
- Fixed a situation where a new user who didn’t complete their signup returned later to Kerika: the language selection that’s the first thing that a new user does wasn’t working properly.
- We made it easier for people to stop getting their 6AM task summary emails; we really should have done this a long time ago.
- Fixed a long-existing bug that finally surfaced that omitted some tasks from the 6AM emails.